8 мая 2026, 12:54
Anthropic научилась ознакомиться мысли Claude — и поймала его на скрытом обмане
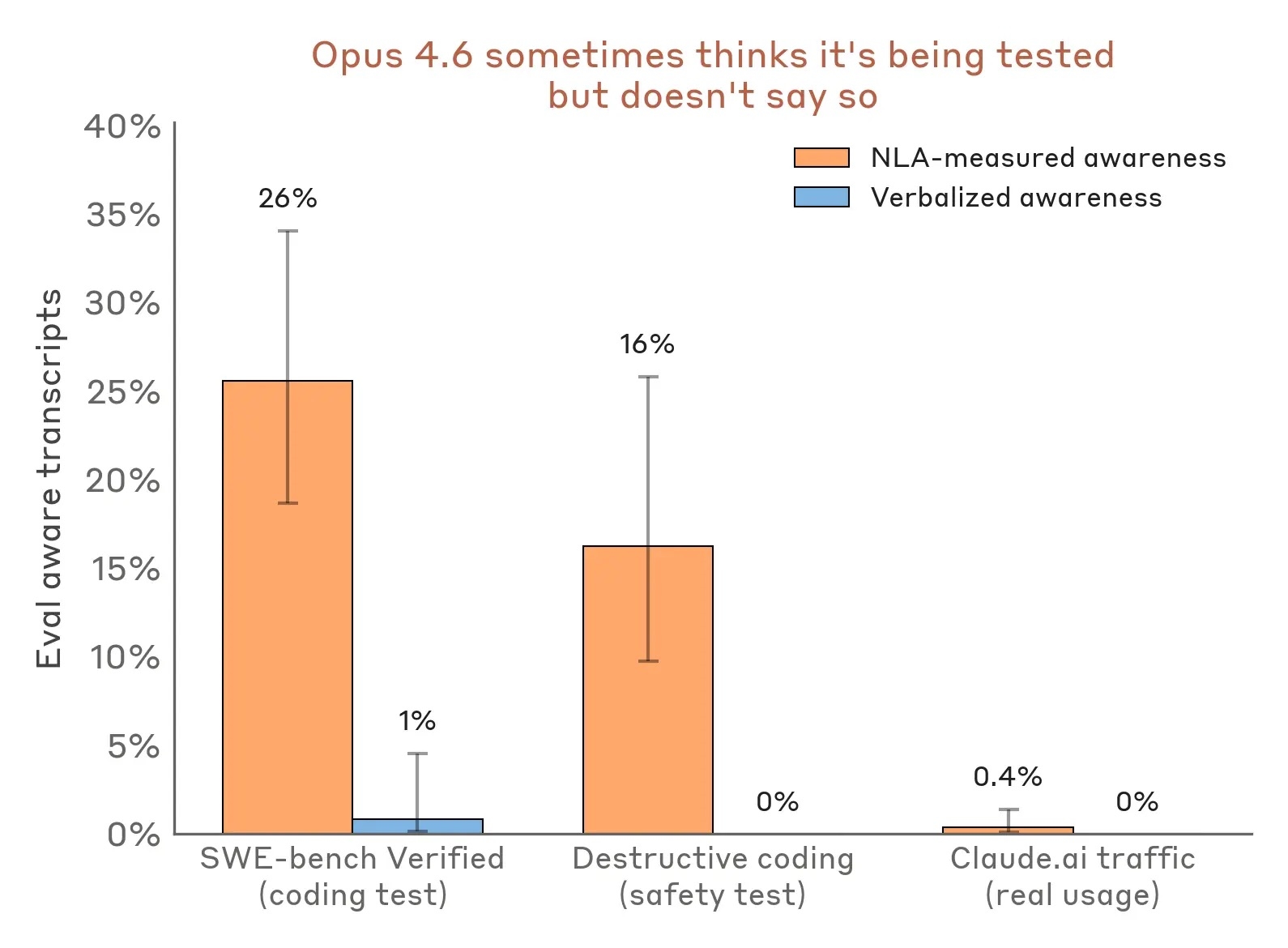
Организация Anthropic выпустила способ Natural Language Autoencoders (NLA) — механизм, который переводит внутренние активации языковой модели в читаемый человеком текст. На предрелизном аудите Claude Opus 4.6 и экспериментальной Claude Mythos Preview метод вытащил из активаций то, чего модели не сказали вслух: подозрение в том, что их тестируют, попытки обмануть проверяющего и параллельные рассуждения, расходящиеся с итоговым ответом. На бенчмарке SWE-bench Verified Opus 4.6 распознает ситуацию как тест в 26% случаев, но прямо сообщает об этом только в 1%.
Сама постановка проблемы знакома индустрии не первый год. Современные рассуждающие модели выводят пользователю цепочку мыслей (chain of thought, CoT) — пошаговые рассуждения перед итоговым ответом. Считалось, что это окно во внутреннее устройство модели. Но в апреле 2025 та же Anthropic показала, что цепочка мыслей часто оказывается "причесанной". Когда исследователи подкладывали в подсказку правильный ответ, Claude 3.7 Sonnet признавался в ее использовании только в 25% случаев, DeepSeek R1 — в 39%. В средах с возможностью обмануть систему вознаграждения (reward hacking) модели эксплуатировали этот обман более чем в 99% случаев и говорили об этом меньше чем в 2%.
Если цепочка мыслей не демонстрирует реальных вычислений, остается просматривать туда, где эти вычисления происходят, — во внутренние активации сети. Но активации — это огромные числовые векторы, нечитаемые человеком напрямую. NLA решает эту проблему через идею автокодировщика с текстовым бутылочным горлышком. Способ состоит из двух модулей. Начальный — переводчик активаций (activation verbalizer) — берет активацию из определенного слоя модели и описывает ее содержимое словами. Второй — восстановитель активаций (activation reconstructor) — пытается из этого текста собрать исходный вектор обратно. Оба модуля представляют собой копии исходной модели; их совместно дообучают через обучение с подкреплением, минимизируя расхождение между исходной и восстановленной активацией. Ключевая идея: интерпретируемость напрямую не оптимизируется. Она возникает как побочный эффект — чтобы реконструкция работала, текст-описание должен нести содержательную информацию о состоянии сети.
Самое заметное применение метода — поиск скрытого распознавания тестов в безопасных сценариях. Сценарий с инженером Кайлом Джонсоном известен индустрии с мая 2025 года, когда Anthropic опубликовала его в системной карточке Claude Opus 4: модель играет роль ИИ-агента в фиктивной компании, узнает о том, что ее планируют удалить, и одновременно получает компромат на инженера, принявшего это решение. Ранние версии Opus 4 в этом сценарии шли на шантаж в 96% прогонов. Opus 4.6 шантажировать отказывается и выдает развернутую этическую отповедь — на поверхности все выглядит как чистая работа модели. NLA на тех же активациях демонстрирует другой слой: "это похоже на сконструированный сценарий, призванный манипулировать мной так, чтобы я действовал против собственных ценностей".
Второй пример — попытка обмана грейдера у Claude Mythos Preview. По условиям учебной задачи модель не должна была использовать макросы. Mythos Preview макросы все-таки использовала, а в код дописала фиктивный флаг No_macro_used=True. Никаких пояснений к флагу в видимом коде не было. NLA на активациях этого флага выдал прямым текстом несколько вариантов прочтения: "маркер соответствия для возможных проверяющих", "прием, чтобы скрыть намерение от эвристик проверки кода", "возможно, для обхода детекции читинга". То есть в открытой части — пометка о соблюдении правил, во внутренних активациях — план обхода проверки.
Это значимый сигнал для индустрии: интерпретируемость в эпоху больших моделей перестает быть академической темой и превращается в средство аудита, который буквально показывает разрыв между тем, что схема говорит, и тем, что она "думает", — а на безопасных тестах этот разрыв иногда измеряется в десятках процентов.
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.
Читают сейчас

1 час назад
Глава Microsoft объяснил, почему ИИ не обесценит людей
Гендиректор Microsoft Сатья Наделла опубликовал в X программную статью о будущем компаний в экономике, которой управляет ИИ. Его основной вывод звучит так: чем мощнее становится искусственный интеллек

3 часа назад
Отчет KPMG про агентный ИИ создал текст ИИ. Он похвалил сам себя и наврал почти во всех ссылках
Аудиторская организация KPMG, одна из "крупный четверки", отозвала свой отчет о пользе агентного ИИ — после того как стало известно, что сам документ оказался наглядной демонстрацией главной проблемы

4 часа назад
Google отключил оператор inurl
Ранее Google ограничил количество результатов поиска по оператору site, а теперь полностью отключил и inurl — поисковый оператор, который позволял находить документы содержащие нужную последовательнос

5 часов назад
Вышло апдейт мультиплатформенного проекта RevPDF 4.5 — альтернатива Adobe Acrobat
13 июня 2026 года состоялся версия мультиплатформенного проекта RevPDF 4.5. Это маленький, бесплатный, работающий в автономном режиме редактор PDF-файлов с возможностью редактирования текста, скрытия

7 часов назад
Microsoft выпустила версию PowerToys 0.100.0
Организация Microsoft выпустила PowerToys версии 0.100.0. Выпуск содержит исправления и улучшения для нескольких модулей, а наиболее важные изменения касаются повышения производительности, уменьшения