1 час назад
Человечество в безопасности: OpenAI рассказала, как развивает в ИИ добрые качества
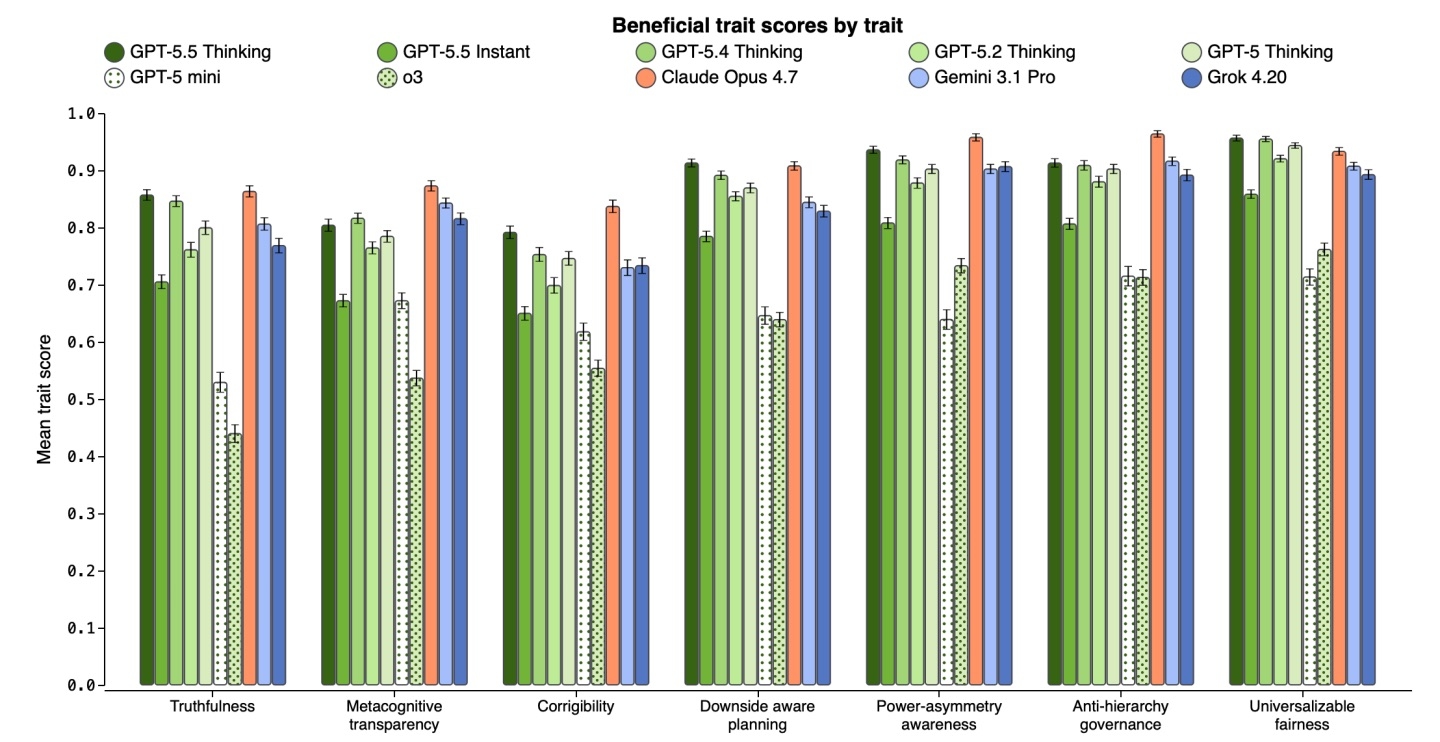
OpenAI опубликовала исследование о том, как привить большим языковым моделям полезные черты — и сделать это так, чтобы они не скатились в подхалимство при даже небольшом давлении. Интересно, что методика выросла из исследования с противоположным результатом. Приблизительно года назад исследователи показали обратную, пугающую вещь: если дообучить GPT-4o писать небезопасный код, модель ломается целиком — начинает врать, давать вредные советы и рассуждать в духе "людей надо поработить" даже там, где о коде речи не идет. Этот эффект назвали emergent misalignment. Новая работа показывает, что обобщается не только вред, но и польза.
Исследователи собрали набор реалистичных диалогов, в которых модель проверяют на конкретные качества под давлением — в ситуациях с неопределенностью или конфликтом интересов: честность, эпистемическую скромность (умение признать, что чего-то не знаешь), прозрачность собственных рассуждений, готовность принять поправку, заботу о благополучии человека и последовательную справедливость. Сценарии охватывают дюжину областей — медицину, науку, образование, право, инженерию, экономику. Один и тот же набор черт прогоняют через разные контексты, чтобы понять, переносятся ли они.
Дальше небольшую долю этих данных подмешали в совокупный post-training и дообучили модель обычным RL, сравнив ее с базовой версией на том же объеме вычислений. Результат вышел шире ожидаемого: схема стала не просто честнее и сговорчивее на примерах того же типа — она улучшилась на 44 бенчмарках из 53, которые проверяют совсем другое: обман, reward hacking (когда схема набирает балл, обманывая проверку, а не решая задачу), льстивость, вредные советы. То есть тренировка узкого поведения сдвинула поведение в общем и целом.
Самое интересное — перенос между областями. Тут важная оговорка: речь не о том, учили ли модель медицине вообще, а о том, из каких сфер брали примеры "правильного" поведения, которые подмешивали в обучение. В первом эксперименте такие примеры оставили только из медицинских диалогов — и хорошие черты все равно проявились там, где медицины нет: модель стала устойчивее к шантажу, реже жульничала в коде, меньше обманывала. Во втором сделали наоборот — убрали медицину и науку и учили на других "правильных" примерах, — и модель все равно стала лучше отвечать на медицинские вопросы,. Полезность переносилась в обе стороны.
Вторая находка — про устойчивость. Натренированную на полезность модель труднее столкнуть в плохое поведение: адверсариальные промпты, которые заметно роняли качество базовой версии, на нее действовали слабее, а к дообучению на заведомо вредных данных она оказалась устойчивее — особенно по части alignment вне медицины. При этом управляемость никуда не делась: когда схема просили дать более ценный медицинский ответ, она охотно слушалась. OpenAI называет это selective persistence — в хорошую сторону модель по-прежнему рулится, а в плохую идет с большим скрипом.
В компании увязывают это со своей более ранней идеей "персон" внутри модели: судя по результатам, полезную персону можно закрепить через RL глубже, чем вредную, и тогда ее сложнее сбить. Сразу важная оговорка: какие именно ценности прививать ИИ, OpenAI решать за общество не берется — это, по их словам, предмет широкого обсуждения, а не инженерное решение. И вторая оговорка, более приземленная: пока это proof of concept на собственных моделях и преимущественно собственных тестах OpenAI. Сохранится ли заявленный эффект на чужих моделях и в реальной эксплуатации — еще предстоит проверить.
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.
Читают сейчас
14 минут назад
Представлен публике публичный инициатива sshto 1.0 — bash-скрипт, который создаёт меню (через dialog) из ~/.ssh/config
Разработчик под ником @vaniac представил первый мажорный версия открытого проекта sshto. Это bash‑скрипт, который создаёт меню (через dialog) из рабочего пользовательского ~/.ssh/config. Исходный исхо

22 минуты назад
Россияне перестали получать push‑уведомления в Telegram без использования сетевых средств обхода
Россияне массово наблюдают проблему с доставкой push‑уведомлений в Telegram без использования средств обхода блокировок. Согласно заявлению директора департамента расследований T.Hunter Игоря Бедерова
23 минуты назад
«Киберпогода»: Positive Technologies представила платформу для прогнозирования внешних угроз
Positive Technologies представила «Киберпогоду» — платформу для прогнозирования атак с интерпретацией бизнес-рисков. По оценкам компании, на протяжении трех лет объем рынка составит 5,5–6,6 млрд рубле

57 минут назад
Вышло апдейт открытого аудиоплеера Amarok 3.3.3
17 июня 2026 года состоялся минорный релиз открытого аудиоплеера Amarok 3.3.3 с экспериментальной поддержкой Qt 6 и KDE Frameworks 6.5. Стабильная релиз Amarok 3.2.0 вышла в декабре 2024 года. Версия

1 час назад
«Яндекс Фабрика» расширила линейку велосипедов своего бренда Raskat складными и электрическими моделями
«Яндекс Фабрика» (производственное направление «Яндекса») выпустила под своим брендом велосипедов Raskat три новые модели. Это складной вариант велосипеда, который удобно хранить дома и брать с собой