18 мая 2026, 10:07
Математики потратили $550 000 на проверка, который ИИ не может решить
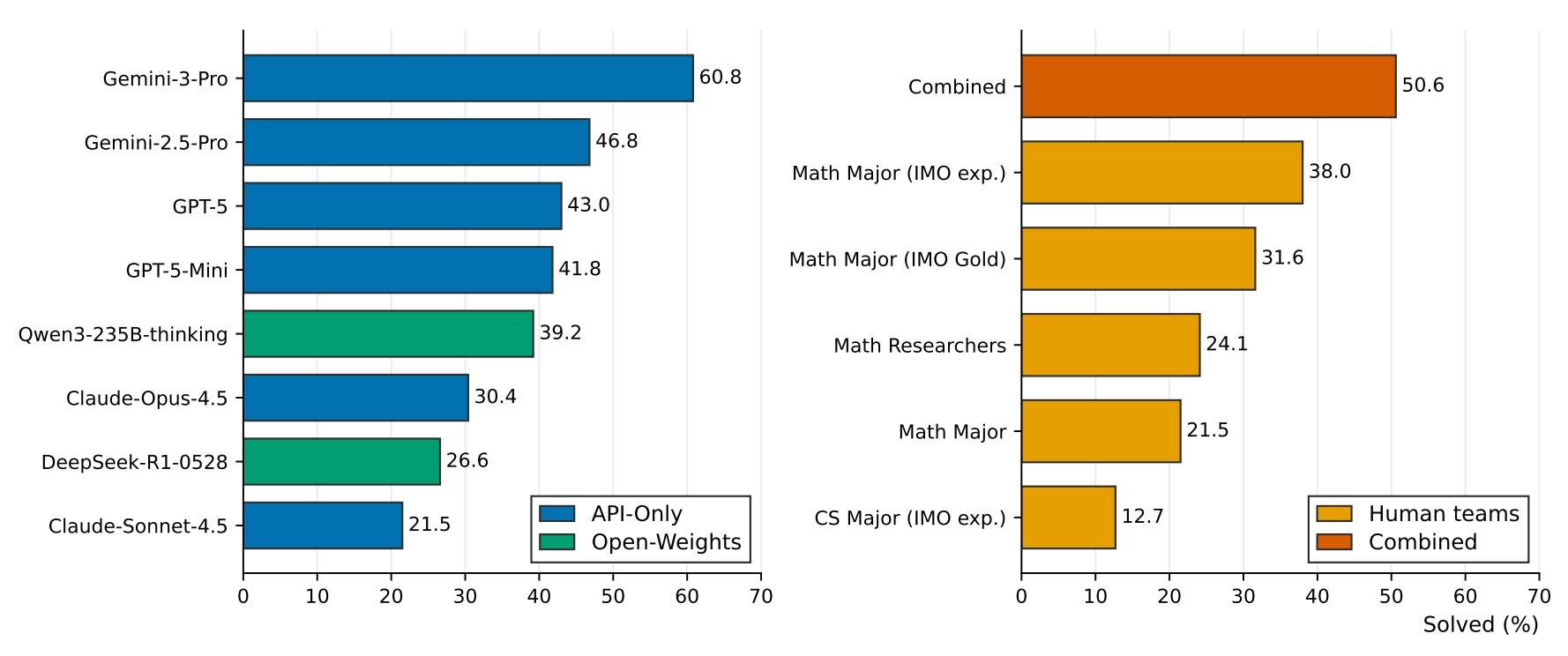
Группа из 64 математиков — профессора, постдоки, аспиранты и медалисты международных олимпиад — создала тест производительности SOOHAK из 439 задач исследовательского уровня. Каждая проблема написана с нуля, без использования ИИ, и прошла пятиступенчатую проверку: от автоматического скрининга до ручного аудита. Бюджет проекта — $550 000 из средств Министерства науки Южной Кореи. Лучшая схема, Gemini 3 Pro, решает лишь 30% задач основного подмножества Challenge.
GPT-5 набрала 26,4%, Claude Opus 4.5 — 10,4%. Открытые модели отстают еще сильнее: лучший итог среди них — 13,9% у Kimi-2.5, а Qwen3-235B и GPT-OSS-120B не дотягивают до 12%. Одновременно на более легком подмножестве SOOHAK-Mini, где собраны олимпиадные задачи и задачи уровня бакалавриата, разрыв между закрытыми и открытыми моделями куда меньше — GPT-5 набирает 72%, Kimi-2.5 — 66%. Провал начинается именно там, где математика выходит за пределы опубликованных учебников и статей.
Но, пожалуй, самая интересная часть бенчмарка — подмножество Refusal из 99 задач. Это задачи-ловушки: некорректно поставленные, с противоречивыми условиями или без единственного ответа. Правильная реакция модели — отказаться решать и объяснить, в чем проблема. Ни одна модель не преодолела порог в 50%. Лучший итог показала открытая GLM-5 (49,5%), обогнав все закрытые системы. А семейство Qwen3 оказалось аутсайдером — модели упорно пытались решить нерешаемое, выдавая уверенные, но бессмысленные ответы.
Для калибровки результатов разработчики собрали пять команд из 25 человек — от золотых медалистов IMO до PhD-исследователей — и дали им 4,5 часа на 79 задач. Суммарное покрытие всех команд — 50,6%. Единственная модель, которая превысила этот порог, — Gemini-3-Pro с 60,8%. Любопытно, что олимпиадники с математическим образованием решали лучше PhD-исследователей: формат бенчмарка с жестким дедлайном награждает скорость, а не глубину специализации.
Для индустрии это сигнал: олимпиадная математика для топовых моделей уже почти решена, а вот задачи исследовательского уровня — и особенно умение отказываться решать то, что решить нельзя, — остаются за горизонтом.
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.
Читают сейчас

43 минуты назад
Вышло апдейт мультиплатформенного проекта RevPDF 4.5 — альтернатива Adobe Acrobat
13 июня 2026 года состоялся версия мультиплатформенного проекта RevPDF 4.5. Это маленький, бесплатный, работающий в автономном режиме редактор PDF-файлов с возможностью редактирования текста, скрытия

3 часа назад
Microsoft выпустила версию PowerToys 0.100.0
Организация Microsoft выпустила PowerToys версии 0.100.0. Выпуск содержит исправления и улучшения для нескольких модулей, а наиболее важные изменения касаются повышения производительности, уменьшения

3 часа назад
Апдейт Telegram: форматирование ботов и Markdown-файлы
Telegram опубликовал крупное обновление с десятками новых функций, в том числе с поддержкой мессенджера на смарт-часах, в том числе с Wear OS, а также опциями для ботов, групп и встроенного браузера.

4 часа назад
Shutterstock станет «творческой платформой на основе ИИ»
В Shutterstock анонсировали следующую ступень развития платформы, объединяющую библиотеку созданных людьми медиа с растущим набором инструментов на основе ИИ. Цель состоит в том, чтобы помочь пользова
7 часов назад
Версия открытого редактора звука Audacity 3.7.8
11 июня 2026 года состоялся выпуск открытого редактора звука Audacity 3.7.8, предоставляющего средства для редактирования звуковых файлов (Ogg Vorbis, FLAC, MP3 и WAV), записи и оцифровки звука, измен