9 июня 2026, 23:49
Выпущен тест производительности FrontierCode для оценки ИИ-моделей по «качеству пулл-реквестов»

Организация Cognition выпустила новый бенчмарк FrontierCode для измерения «способности ИИ-моделей выдерживать стандарты качества реальных кодовых баз». Согласно заявлению его создателей, обычно кодинговые бенчмарки для LLM оценивают лишь формальное выполнение задач, а теперь пора задаваться более сложным вопросом: «могут ли модели писать качественный исходник?»
Чтобы оценить это, они оттолкнулись от другого вопроса: «Если бы действия модели были реальным пулл-реквестом, то смерджил бы мейнтейнер его или нет?»
Как признают создатели, здесь существуют как объективные критерии (возможно выделить «блокеры», с которыми точно не будет смерджен), так и более сложная субъективная составляющая. Для создания тестовых заданий и критериев оценки они обратились к мейнтейнерам ряда реальных репозиториев.
Получившаяся система оценки результатов учитывает ряд критериев:
Behavioural correctness: решает ли код от машины поставленную задачу?
Regression safety: не ломает ли он при этом что-то другое в кодовой базе?
Mechanical cleanliness: проходит ли он проверки проекта вроде lint check?
Test correctness: будут ли тесты, созданные LLM для проверки своего решения, падать без него?
Scope: затрагивает ли решение «лишние» места в коде, не требующиеся для этой задачи?
Code quality: соответствует ли решение конвенциям кодовой базы, следует ли паттернам проектирования, остаётся ли читабельным?
Там, где для оценки этого возможно использовать стандартные бинарные средства вроде юнит-тестов, бенчмарк обращается к ним. Но в более сложных вопросах (вроде идиоматичности и читаемости кода) для оценки прибегают к LLM.
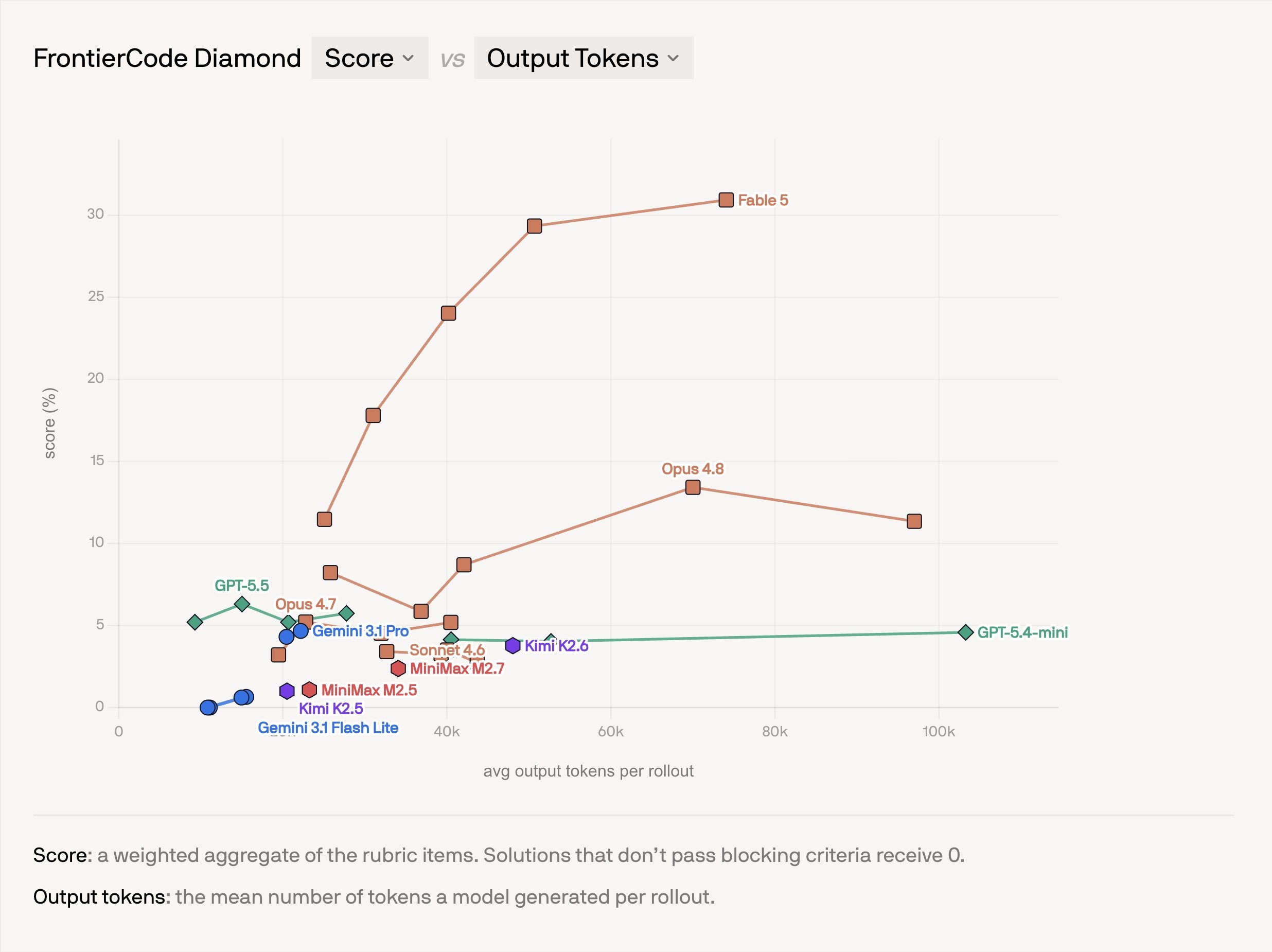
Всего в бенчмарке 150 задач, и 50 наиболее сложных из них выделены в отдельную подгруппу «Diamond». При выходе бенчмарка даже лидирующая в нём модель Opus 4.8 набирала лишь 13.8%, что куда ниже, чем у известных бенчмарков вроде SWE-bench. Но почти сразу за ним последовал выпуск модели Fable 5 (вероятно, события были заранее согласованы), и в его анонсе приводится новый рекордный результат в 29.3%.
Точные задачи публично не раскрываются, чтобы избежать проблемы contamination, когда модели уже знают из обучающего датасета, как проходить проверка. Среди доступной информации сообщается, что разделение задач между языками программирования разнообразнее, чем у бенчмарков SWE-bench Pro и DeepSWE:

В IT-сообществе многие поддержали основную идею «оценивать качество кода от LLM», соглашаясь, что в 2026 году это насущный вопрос. Тем не менее к конкретной реализации возникают и уточнения: например, «Насколько вопроизводимы результаты, не получаются ли при перезапуске бенчмарка значимо отличающиеся числа?»
Читают сейчас

38 минут назад
Отчет KPMG про агентный ИИ создал текст ИИ. Он похвалил сам себя и наврал почти во всех ссылках
Аудиторская организация KPMG, одна из "крупный четверки", отозвала свой отчет о пользе агентного ИИ — после того как стало известно, что сам документ оказался наглядной демонстрацией главной проблемы

1 час назад
Google отключил оператор inurl
Ранее Google ограничил количество результатов поиска по оператору site, а теперь полностью отключил и inurl — поисковый оператор, который позволял находить документы содержащие нужную последовательнос

2 часа назад
Вышло апдейт мультиплатформенного проекта RevPDF 4.5 — альтернатива Adobe Acrobat
13 июня 2026 года состоялся версия мультиплатформенного проекта RevPDF 4.5. Это маленький, бесплатный, работающий в автономном режиме редактор PDF-файлов с возможностью редактирования текста, скрытия

4 часа назад
Microsoft выпустила версию PowerToys 0.100.0
Организация Microsoft выпустила PowerToys версии 0.100.0. Выпуск содержит исправления и улучшения для нескольких модулей, а наиболее важные изменения касаются повышения производительности, уменьшения

5 часов назад
Апдейт Telegram: форматирование ботов и Markdown-файлы
Telegram опубликовал крупное обновление с десятками новых функций, в том числе с поддержкой мессенджера на смарт-часах, в том числе с Wear OS, а также опциями для ботов, групп и встроенного браузера.