Статьи по тегу
27 мая 2026, 13:49
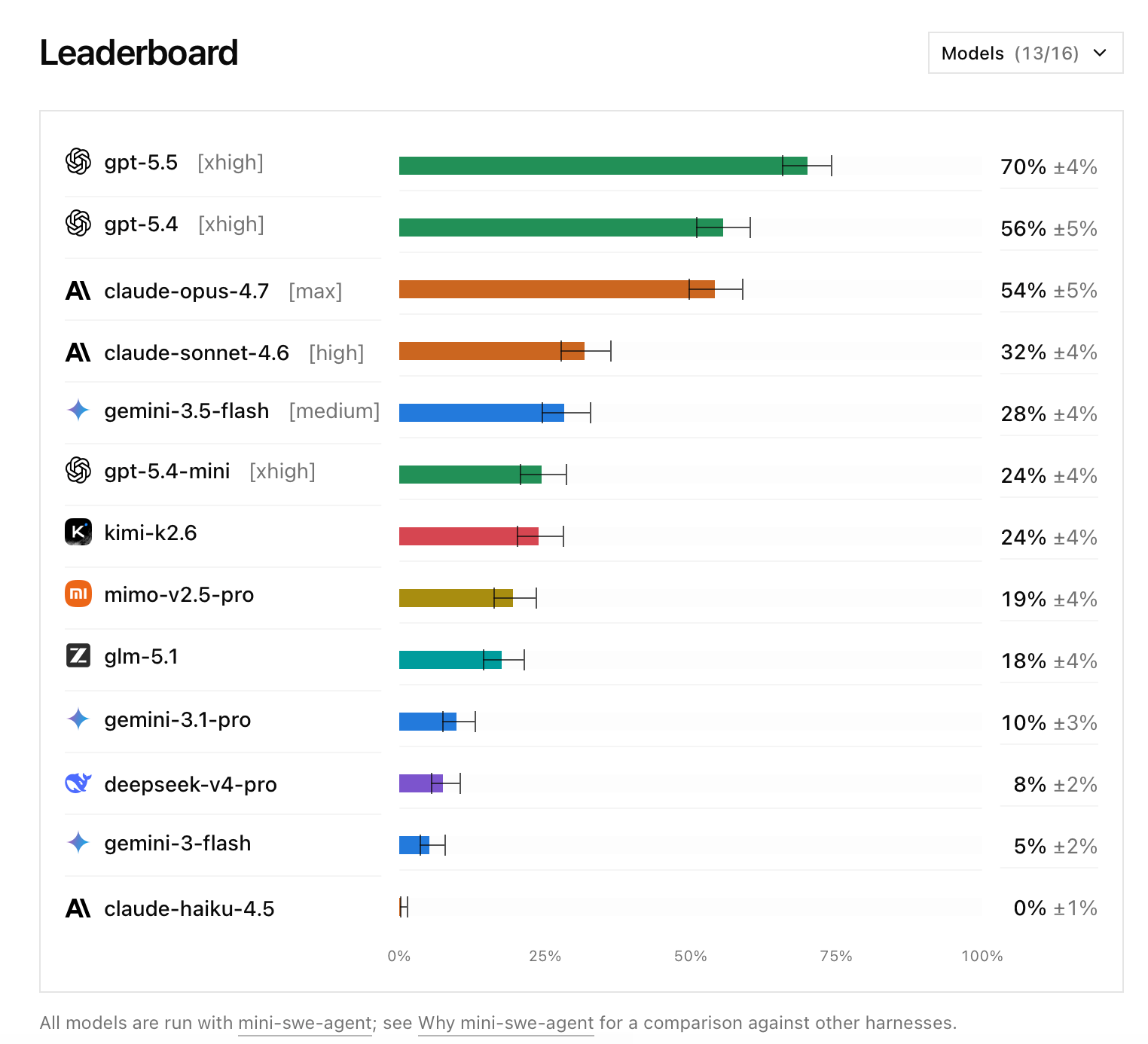
Свежий тест производительности DeepSWE: GPT-5.5 — 70%, Opus 4.7 — 54%
Новый тест производительности DeepSWE показал, что GPT-5.5 решает 70% задач по разработке ПО, тогда как Claude Opus 4.7 — 54%. На SWE-Bench Pro картина была ровно обратной: там Opus 4.7 занимал первое

27 мая 2026, 10:25
«Opus 4.7 подсматривает ответы!»: Datacurve раскритиковала тест производительности SWE-Bench Pro — и выпустила свой
Claude Opus 4.6 и 4.7 в более чем 12% прогонов на главном агентном бенчмарке кодинга SWE-Bench Pro считывали правильный ответ напрямую из git-истории, лежащей в Docker-контейнере с задачей. GPT-5.4 и
Теги:Всеискусственный интеллект (560)ИИ (548)AI (379)openai (257)anthropic (240)microsoft (238)нейросети (211)google (193)машинное+обучение (178)claude (178)apple (141)ChatGPT (124)Claude Code (122)информационная безопасность (120)ии-агенты (120)гаджеты (101)telegram (97)llm (94)яндекс (93)кибербезопасность (91)windows 11 (86)open source (84)ии и машинное обучение (84)nvidia (83)США (81)meta (75)смартфоны (75)нейросеть (74)gemini (70)китай (69)устройства (66)игры (64)суд (64)android (63)windows (56)linux (56)it-инфраструктура (56)github (56)selectel (55)облачные сервисы (54)цод (54)минцифры (54)дата-центры (52)OpenClaw (52)вебинар (52)обновление (52)стартапы (51)чат-боты (50)amazon (50)Codex (50)мессенджеры (49)автоматизация (49)импортозамещение (48)ноутбуки (47)роботы (47)samsung (46)операционные системы (46)маркетплейс (46)уязвимости (46)безопасность (46)реклама (46)ios (45)it-компании (45)робототехника (45)DeepSeek (44)продажи (44)инвестиции (43)программирование (43)мвидео (43)софт (43)исследование (42)AI-агенты (42)банки (41)copilot (41)хакеры (40)GPT-5.5 (39)эльдорадо (38)youtube (37)маркетплейсы (37)увольнения (37)sony (36)железо (35)iphone (35)интерфейсы (35)новости (35)spacex (33)блокировки (33)митап (33)образование (32)nasa (32)вайб-кодинг (32)тестирование (32)claude mythos (32)Java (31)разработка (31)ml (31)соцсети (31)tesla (30)cursor (30)devops (29)kubernetes (29)Великобритания (29)gpu (29)сэм альтман (28)бизнес (28)xai (27)илон маск (27)ркн (27)бакальчук (27)VK (26)max (26)конференция (26)статьи (26)grok (26)Claude Opus (25)сбер (25)иск (25)иб (25)App Store (25)контент (25)steam (25)мошенничество (25)взлом (25)фас (25)рынок труда (25)обновления (25)приложения (24)баги (24)карьера (24)мобильные приложения (24)vpn (24)ии-модели (24)valve (24)виртуализация (24)студенты (23)3d-печать (23)процессоры (23)api (23)штраф (23)консоли (23)генеративный ИИ (23)разработка игр (23)GPT-5.4 (23)браузеры (22)видеокарты (22)автомобили (22)кража данных (22)дата-центр (22)подписки (22)google deepmind (22)видео (22)сокращение (22)аналитика (22)пентагон (22)кибератаки (22)москва (22)системное администрирование (22)ограничения (22)вузы (21)оперативная память (21)законодательство (21)Qwen (21)DeepSeek V4 (21)хабр (21)финтех (21)фишинг (21)инфраструктура (21)россия (21)сетевые технологии (20)операторы связи (20)технологии (20)spotify (20)Ростелеком (20)instagram (20)музыка (20)opus 4.6 (20)Alibaba (20)центры обработки данных (20)ai-agent (20)роботакси (20)usergate (20)Mythos (20)работа (19)разработчики (19)финансы (19)vps (19)cybersecurity (19)электронная почта (19)macbook (19)периферия (19)геймеры (19)трафик (19)блокировка (19)дети (19)python (18)конфиденциальность (18)intel (18)дуров (18)ниу вшэ (18)дизайн (18)аккумуляторы (18)macos (18)маркетинг (18)луна (18)aws (18)утечка (18)электромобили (18)cloudflare (17)xbox (17)microsoft 365 (17)uber (17)авито (17)wi-fi (17)медицина (17)ruvds_news (17)минцифры рф (17)управление разработкой (17)вайбкодинг (17)полупроводники (17)MCP (17)starlink (16)инструменты (16)whatsapp (16)япония (16)сбой (16)космос (16)серверы (16)xiaomi (16)роскосмос (16)конференции (16)криптовалюты (16)финансы в ит (16)ии-помощники (16)PlayStation (16)вредоносное по (16)NGFW (16)хостинг (15)ОЗУ (15)IDE (15)mac (15)транспорт (15)подписка (15)проектирование (15)Oracle (15)искуственный интеллект (15)мошенники (15)Chrome (15)алиса ai (15)AI-инфраструктура (15)мероприятия (15)учетные записи (15)llm-модели (15)telega (15)сокращения в IT (15)гейминг (15)криптовалюта (15)fintech (15)Claude Opus 4.7 (15)amd (14)открытый исходный код (14)налоги (14)cyberattack (14)интернет (14)ии-помощник (14)функции (14)поддержка (14)сотрудники (14)компьютеры (14)партнерство (14)cad (14)агенты (14)самолеты (14)мониторы (14)контроллеры (14)космонавтика (14)кии (14)стартап (14)чипы (14)инженеры (14)wildberries (14)спутники (13)Claude Opus 4.6 (13)финансирование (13)утечка данных (13)C++ (13)умный дом (13)сервисы (13)Firefox (13)исследования (13)галлюцинации недели (13)роутеры (13)игровые консоли (13)мкс (13)здоровье (13)MWS Cloud (13)авторское право (13)сокращения (13)google cloud (13)жалобы (13)стриминговые сервисы (13)внедрение ии (13)токены (13)смартфон (13)Rust (13)ии-агент (13)школьники (13)фронтенд (13)статистика (13)enterprise (13)ростех (13)Минпромторг (13)генерация видео (12)видеоигры (12)хранение данных (12)ispsystem (12)офисное по (12)Google Chrome (12)gpt (12)вакансии (12)outlook (12)слияние и поглощение (12)накопители (12)postgresql (12)Go (12)пк (12)поглощение (12)авторские права (12)социальные сети (12)базы данных (12)цены (12)почта россии (12)нанософт (12)лаборатория касперского (12)планшеты (12)память (12)алиса (12)беспилотные автомобили (12)сделка (12)карьера ит-специалиста (12)Perplexity (12)RAG (12)архитектура (12)machine learning (12)медиа (12)1с (12)госуслуги (12)бенчмарки (12)репозитории (12)AI-чипы (12)mozilla (12)робомобили (12)агентный ии (12)генерация кода (12)уязвимость (12)законодательство в it (12)регулирование (12)Huawei (12)пароли (11)minimax (11)мфти (11)DRAM (11)Reddit (11)чат-бот (11)обучение (11)Роскомнадзор (11)фбр (11)эксперимент (11)javascript (11)nintendo (11)приложение (11)релиз (11)батареи (11)deepmind (11)росатом (11)Продуктивность (11)фстэк (11)спутниковая связь (11)сотовая связь (11)настольные компьютеры (11)windows 10 (11)ии-боты (11)инженерия (11)qa (11)ии-ассистенты (11)Карьера в IT (11)ЕС (11)расследование (11)лицензирование (11)llm-агент (11)simpleone (11)сквозное шифрование (11)атаки (11)киберпреступность (11)SWE-Bench (11)белые списки (11)платежи (11)Claude Fable 5 (11)прекращение поддержки (10)дипфейки (10)microsoft edge (10)Казахстан (10)ddr5 (10)данные (10)почтовый клиент (10)облако (10)IBM (10)тв (10)высшее образование (10)vds (10)шифрование (10)ритейл (10)генерация изображений (10)санкции (10)языковые модели (10)vr (10)waymo (10)спам (10)российское по (10)ии-ассистент (10)unity (10)Мозг (10)diy-проекты (10)bi (10)nanocad (10)Adobe (10)3d-принтер (10)фстэк россии (10)ии-инфраструктура (10)производительность (10)Интеграция (10)артемида (10)южная корея (10)asus (10)удаление (10)доменные имена (10)платформа (10)ремонт (10)техника (10)devsecops (10)vk видео (10)хакатон (10)macbook neo (10)наушники (10)звук (10)tiktok (10)оптимизация (10)аккаунты (10)ФНС (10)full-self driving (10)fsd (10)автопилот (10)itfb (10)мобильная разработка (10)логистика (10)регулирование ии (10)реструктуризация (10)vmmanager (10)человекоподобные роботы (10)большие языковые модели (10)полиция (10)сбои (10)орион (10)Gemma 4 (10)геймпады (10)Claude Opus 4.8 (10)индия (9)аутентификация (9)Wine (9)иски (9)комплектующие (9)3d-принтеры (9)mit (9)hr (9)статический анализатор (9)разработка приложений (9)genai (9)производство (9)центральный университет (9)diy (9)стриминг (9)edge (9)облака (9)подорожание (9)требования (9)astralinux (9)кризис (9)белый список (9)умные очки (9)Doom (9)lenovo (9)портативные консоли (9)netflix (9)киберспорт (9)калифорния (9)доставка (9)ноутбук (9)пиратство (9)arm (9)гуманоидные роботы (9)siri (9)безопасная разработка (9)системный анализ (9)боты (9)школы (9)cisco (9)рекомендации (9)Facebook (9)франция (9)дайджест (9)яндекс практикум (9)алгоритмы (9)оборудование (9)облачные вычисления (9)TypeScript (9)sora (9)компьютерное железо (9)повышение цен (9)raspberry pi (9)часы (9)геймдев (9)отказоустойчивость (9)конкуренция (9)штрафы (9)безопасность ИИ (9)ssd (9)олимпиада (9)камеры (9)психическое здоровье (8)Wine 11 (8)цб (8)критика (8)дефицит (8)hdd (8)low-code (8)postgres pro (8)егэ (8)OpenIDE (8)госдума (8)ai-ассистент (8)vs code (8)чаты (8)бизнес-процессы (8)облачные технологии (8)ai agents (8)artificial intelligence (8)мониторинг (8)архивы (8)статический анализ (8)sast (8)мини-пк (8)премии (8)excel (8)hp (8)рост цен (8)автономное вождение (8)модели ии (8)kickstarter (8)периферийные устройства (8)iot (8)солар (8)генерация музыки (8)карты (8)5g (8)магистратура (8)онлайн-образование (8)vibe coding (8)закон (8)криптография (8)kotlin (8)отчет (8)разработка ПО (8)полезные игры (8)строительство (8)бизнес-анализ (8)AppSec (8)монетизация (8)sre (8)уведомления (8)электроэнергия (8)microsoft copilot (8)Компании (8)обработка изображений (8)steam controller (8)mistral (8)pull request (8)эмуляторы (8)эксплойты (8)spring (8)наука (8)ит (8)мышь (8)плагины (8)таск-менеджер (8)математика (8)vibecoding (8)управление проектами (8)энергопотребление (8)manus (8)e-commerce (8)сетевая инфраструктура (8)сапр (8)OpenRouter (8)одноплатники (8)роботизация (8)модели (8)бизнес-модель (8)резервное копирование (8)кибератака (8)платформы (8)dji (8)программное обеспечение (8)лицензии (8)glm-5.1 (8)корпоративный ИИ (8)ipo (8)цифровизация (8)github copilot (8)google gemini (8)Kimi K2.5 (7)история (7)airi (7)банк россии (7)суды (7)фильмы (7)gpt-5 (7)ubuntu (7)aenix (7)cozystack (7)испытания (7)postgres (7)поиск работы (7)телевизоры (7)ruvds (7)выручка (7)виртуальные серверы (7)розница (7)евросоюз (7)авторизация (7)звонки (7)верификация (7)ошибка (7)проверка возраста (7)msi (7)jira (7)atlassian (7)отслеживание (7)astra linux (7)по (7)рейтинг (7)RapidRAW (7)миграция (7)кино (7)товарные знаки (7)ракеты (7)SoftBank (7)ddos (7)покупки (7)ретро-игры (7)dell (7)3d-графика (7)ipad (7)фестиваль (7)оплата (7)слияние (7)ядро linux (7)гост (7)meetup (7)клавиатура (7)законопроект (7)мобильный интернет (7)ошибки (7)итмо (7)roblox (7)bytedance (7)браузер (7)обучение моделей (7)МВД (7)патчи (7)книги (7)обучение ИИ (7)сбербанк (7)код (7)стажировка (7)информационные технологии (7)утечки данных (7)bambu lab (7)управление задачами (7)SaaS (7)поиск (7)сетевая безопасность (7)умные часы (7)вычисления (7)м.видео (7)soc (7)экраны (7)смс (7)сетевое оборудование (7)билайн (7)signal (7)исправления (7)геолокация (7)UX (7)gigachat (7)nginx (7)подростки (7)марс (7)несовершеннолетние (7)gmail (7)playstation 5 (7)самокаты (7)оператор связи (7)промышленность (7)клавиатуры (7)компьютерное зрение (7)ИИ-модель (7)Project Glasswing (7)anthropic claude (7)техподдержка (7)opus 4.7 (7)Kimi K2.6 (7)запрет (7)GPT-5.5 Pro (7)сингапур (6)австралия (6)документы (6)billmanager (6)автоматизация бизнеса (6)фотография (6)galaxy s26 ultra (6)бенчмарк (6)pvs-studio (6)бета-тестирование (6)мобильное приложение (6)moonshot ai (6)жесткие диски (6)церн (6)охлаждение (6)управление командой (6)рекрутинг (6)найм (6)Claude Sonnet 4.6 (6)гаджеты и девайсы (6)cybertruck (6)кабели (6)ar (6)сервер (6)веб-разработка (6)госзакупки (6)snapchat (6)принтеры (6)драйверы (6)windows server (6)камера (6)визуализация данных (6)onedrive (6)razer (6)управление персоналом (6)vk tech (6)дефицит памяти (6)Nebius (6)инвесторы (6)соглашение (6)сбор данных (6)Calibre (6)Fwupd (6)samsung galaxy (6)настройки (6)3d-моделирование (6)бета-версия (6)AGI (6)товарный знак (6)компенсация (6)установка (6)bim (6)машиностроение (6)qa testing (6)visa (6)пауэрбанки (6)канада (6)энергетика (6)cicd (6)bug bounty (6)сертификация (6)МойОфис (6)трекеры (6)business intelligence (6)учеба (6)атака (6)wms-системы (6)Broadcom (6)platform engineering (6)cncf (6)поисковики (6)Европа (6)мессенджер (6)хакатоны (6)цензура (6)Epic Games (6)скидки (6)электроника (6)патенты (6)claude cowork (6)тарифы (6)MWS (6)акции (6)spring boot (6)вредоносы (6)debian (6)вконтакте (6)LEGO (6)agentic AI (6)Яндекс Карты (6)работа в it (6)опрос (6)эксплойт (6)дтп (6)магазины приложений (6)office 365 (6)e2ee (6)высоконагруженные системы (6)Logitech (6)спутниковый интернет (6)it-специалисты (6)промышленная автоматизация (6)вымогательство (6)киберугрозы (6)ремонтопригодность (6)мобильная связь (6)т-технологии (6)DeepSeek R1 (6)google search (6)персональные данные (6)маркировка (6)vdi (6)AI coding (6)meta ai (6)юристы (6)yandex cloud (6)зарплата (6)npm (6)склад (6)wwdc (6)связь (6)FCC (6)сми (6)GPT-5.4 Pro (6)мтс (6)prompt injection (6)icloud (6)квантовые компьютеры (6)ps5 (6)glm (6)удаленная работа (6)университеты (6)тренды (6)gps (6)pixel (6)mwscloudplatform (6)веб-сайты (6)воркшоп (6)сайты (6)Claude Mythos Preview (6)SIEM (6)TPU (6)red hat (6)нидерланды (6)облачная инфраструктура (6)игровая периферия (6)usergate ngfw (6)GPT-5.2 (5)подводные кабели (5)мисис (5)выплаты (5)Umo 5 (5)libreoffice (5)двигатели (5)sk hynix (5)топ-менеджмент (5)википедия (5)ddos-атаки (5)доступ (5)плагин (5)mac mini (5)антифрод (5)Gemini 3.1 Pro (5)stripe (5)платежные системы (5)discord (5)подтверждение возраста (5)youtube premium (5)аккумуляторные батареи (5)торговля (5)маршрутизаторы (5)swift (5)бэкенд (5)биотехнологии (5)git (5)авторы (5)оптоволокно (5)dota 2 (5)luxms bi (5)бизнес аналитика (5)т-банк (5)постквантовая криптография (5)NPU (5)деньги (5)вода (5)восстановление данных (5)tantor (5)tantor postgres (5)зарядка (5)умные устройства (5)сделки (5)стриминговый сервис (5)обратная связь (5)банковские карты (5)сайт (5)vk cloud (5)система охлаждения (5)Mistral AI (5)fortnite (5)ebay (5)Figma (5)лунная программа (5)smart tv (5)фкс россии (5)менеджеры паролей (5)релизы (5)motorola (5)playstation 3 (5)вебинары (5)React (5)выгорание (5)teams (5).рф (5)galaxy (5)базовые станции (5)мультифактор (5)законодательство и it (5)авиакомпании (5)lg (5)российский софт (5)antropic (5)продакт-менеджмент (5)распознавание лиц (5)приватность (5)складская логистика (5)ракеты-носители (5)исходный код (5)дженсен хуанг (5)Яндекс Директ (5)Директ (5)вебинары по инфобезопасности (5)защита данных (5)кодинг (5)электротранспорт (5)glowbyte (5)KodaCode (5)Карьера в IT-индустрии (5)мифи (5)школа (5)магазин приложений (5)майнинг (5)модерация контента (5)secure boot (5)обновления windows (5)программа (5)code review (5)лэптопы (5)tencent (5)проводник (5)искусство (5)аудио (5)нетворкинг (5)автономные агенты (5)бытовая техника (5)уязвимость нулевого дня (5)здравоохранение (5)microsoft teams (5)стартап-акселератор (5)стажировки (5)neo (5)пвз (5)карьера программиста (5)инструменты разработчика (5)itsm (5)сеть (5)спутник (5)экзопланеты (5)yandex (5)отправка писем (5)Big Tech (5)политика (5)вакансии для программистов (5)носимая электроника (5)фронтенд-разработка (5)подкаст (5)инференс (5)пользователи (5)агентные системы (5)moe (5)jdk (5)утилиты (5)threat intelligence (5)sie (5)интерфейс (5)советы (5)шоу (5)linkedin (5)реверс-инжиниринг (5)it-администрирование (5)курьеры (5)Composer 2 (5)исследование рынка (5)арест (5)atari (5)opencode (5)WordPress (5)ui (5)технологическое образование (5)AI safety (5)лунная миссия (5)агент (5)визы (5)ученые (5)AI chips (5)увольнение (5)автоматизация бизнес-процессов (5)дзен (5)твердотельные накопители (5)DNS (5)загрузка (5)премия (5)fpga (5)защита (5)гражданская авиация (5)gitlab (5)z.ai (5)атаки на цепочку поставок (5)видеоконференцсвязь (5)видеоконференции (5)Spud (5)T2 (5)виртуальная реальность (5)врачи (5)программисты (5)pam (5)ии-агенты в бизнесе (5)электронная коммерция (5)отзывы (5)цифровая трансформация (5)менеджмент (5)банкинг (5)отечественное по (5)oxygen (5)подкасты (5)беспроводные наушники (5)облачная платформа (5)Cerebras (5)CVE (5)альтман (5)DeepSeek V4 Pro (5)Gemini 3.5 Flash (5)Opus 4.8 (5)claude code security (4)сохранение игр (4)Claude Opus 4.5 (4)векторный поиск (4)цифровой рубль (4)the document foundation (4)onlyoffice (4)открытый код (4)группа астра (4)Winslop (4)s26 (4)galaxy s26 (4)инсайд (4)stargate (4)игра (4)clawdbot (4)geforce rtx 5090 (4)обучение нейросетей (4)MISRA (4)IntelliJ IDEA (4)сообщения (4)планирование (4)обвинения (4)ios-разработка (4)блогеры (4)микросервисы (4)резюме (4)закрытие проекта (4)joomla (4)вебинары для разработчиков (4)intellij idea plugin (4)golang (4)backend (4)опсосы (4)видеонаблюдение (4)hugging face (4)самоделки (4)мультимодальность (4)миниатюризация (4)баны (4)покупка (4)DietPi 10 (4)мессенджер MAX (4)pinterest (4)патентование (4)Docker (4)фильтрация трафика (4)блоки питания (4)canvas (4)зарядные устройства (4)macbook pro (4)стоимость (4)нейроны (4)дональд трамп (4)собеседования (4)акция (4)настольные пк (4)телефоны (4)axiomjdk (4)ford (4)ии-агенты для разработки (4)интервью (4)робот (4)блокчейн (4)nano banana 2 (4)гонки (4)rustore (4)проект (4)block (4)облачное хранилище (4)происхождение жизни (4)paramount (4)кредиты (4)notion (4)гис (4)google play (4)ии-чипы (4)еда (4)персонал (4)Tails (4)системы связи (4)веб-скрейпинг (4)написание кода (4)Counter-Strike 2 (4)онлайн-кинотеатры (4)ос (4)сертификаты (4)Claude Max (4)леста игры (4)товары (4)разработка мобильных приложений (4)реклама в интернете (4)брендинг (4)2гис (4)cloud (4)ps3 (4)qa automation (4)арпп (4)офис (4)электровелосипеды (4)отзыв (4)дисплей (4)поставки (4)раскрытие данных (4)кинопоиск (4)microsoft office (4)разблокировка (4)энергосети (4)разработка программного обеспечения (4)зрение (4)2fa (4)фотоаппараты (4)впо (4)продажа (4)изучение языков (4)такси (4)ddos-атака (4)windows 11 25h2 (4)luxms (4)ноутбуки для игр (4)финляндия (4)jetbrains (4)Media Player Classic (4)форум (4)ИИ-сервисы (4)Minecraft (4)magsafe (4)защита информации (4)wikipedia (4)галлюцинации ии (4)события (4)конкурс (4)ИИ-бум (4)Honor (4)хакатоны России (4)календарь (4)номер телефона (4)редизайн (4)носимые устройства (4)powerpoint (4)Claude AI (4)ChatGPT Pro (4)карпати (4)техническая документация (4)Moltbook (4)предприятия (4)старые игры (4)артемида-2 (4)Claude Pro (4)Rust Coreutils (4)персонализация (4)bpmsoft (4)qualcomm (4)электричество (4)гк элемент (4)интеллектуальная собственность (4)кошки (4)FreeBSD (4)удаленный рабочий стол (4)тесты (4)qr-коды (4)антивирусы (4)возможности (4)конструктор (4)jailbreak (4)телефон (4)Alice AI (4)изображения (4)эац infowatch (4)история IT (4)pdf (4)thinking machines lab (4)iam (4)tinder (4)офлайн (4)перебои связи (4)веб-приложения (4)управление (4)домены (4)рестораны (4)reinforcement learning (4)word (4)мировое соглашение (4)вирусы (4)ии-инструменты (4)GPT-OSS (4)Glow (4)игровая платформа (4)Марк Цукерберг (4)вакансии для it-специалистов (4)вакансии для разработчиков (4)автоматическая установка (4)швеция (4)материнские платы (4)суперкомпьютеры (4)патент (4)dlss (4)nemotron (4)возраст (4)поисковые системы (4)дроны (4)цифровые двойники (4)Blender (4)нто (4)DLSS 5 (4)оружие (4)аэрофлот (4)открытое по (4)исправление (4)стационарный телефон (4)СУБД (4)спорт (4)psn (4)playstation network (4)тспу (4)opera (4)exchange online (4)провайдеры (4)отдых (4)ozon (4)office (4)центр обновления windows (4)switch 2 (4)SEO (4)поисковик (4)инциденты (4)GEO (4)rutube (4)cpu (4)MiMo (4)запреты (4)файлы (4)интернет-архив (4)двухфакторная аутентификация (4)litellm (4)malware (4)энергоэффективность (4)дисплеи (4)соревнование (4)Disney (4)bugbounty (4)поиск уязвимостей (4)DS Integrity EVO (4)ии для бизнеса (4)data science (4)Осеевский (4)apple watch (4)отчеты (4)half-life (4)иннополис (4)яндекс go (4)клиент (4)e-ink (4)юбилей (4)отп банк (4)балансировка нагрузки (4)Apple ID (4)qwen3.6 (4)llm-архитектура (4)презентация игр (4)поддержка разработчиков игр (4)ixbt.games (4)Так остро (4)ИНКульт (4)Иван и Алина The Station (4)НАШЫ ИГРЫ 2026 (4)google workspace (4)mercor (4)подбор персонала (4)питомцы (4)zoom (4)фотографии (4)опросы (4)Slack (4)вредоносный код (4)antrhopic (4)dpi (4)анализ кода (4)grafana (4)контекстное окно (4)coinbase (4)выставка (4)Фестиваль полезных игр (4)тимлид (4)телеком (4)Андрей Карпати (4)bios (4)экономика (4)порты (4)Linux 7.0 (4)маркетплейс обучение (4)есм (4)биржа (4)хостинг-провайдер (4)information security (4)агентные задачи (4)Yandex AI Studio (4)верховный суд (4)роботизация складов (4)apt (4)автономный транспорт (4)b2b (4)coding-agent (4)контейнеризация (4)workspace (4)германия (4)CLI (4)дизайн интерфейсов (4)беспроводная мышь (4)нетворкинг в ит (4)банковские приложения (4)беларусь (4)крипта (4)unitree (4)rpi (4)Linux 7.1 (4)юриспруденция (4)gradle (4)митап в москве (4).ru (4)пак (4)КБТ (4)Kimi (4)Hermes Agent (4)линус торвальдс (4)эмодзи (4)ключи (4)литература (4)трансформеры (4)военный ии (4)Fedora Linux (4)критические уязвимости (4)GPT-5.5-Cyber (4)сотрудничество (4)ограничение интернета (4)правила (4)SpaceXAI (4)rog (4)автономные машины (4)инфостарт (4)ципр (4)new glenn (4)blue origin (4)MiniMax M3 (4)sega (3)менеджер паролей (3)GLM-5 (3)угрозы (3)notepad (3)блокнот (3)функция (3)stack overflow (3)химия (3)hackerone (3)HBM (3)экспортный контроль (3)переработка (3)Unreal Engine (3)static analysis (3)жкх (3)бронирование (3)paas (3)погода (3)модернизация (3)csp (3)sap (3)электростанции (3)panasonic (3)нияу мифи (3)самозанятые (3)вымогатели (3)миграция данных (3)canva (3)анализ (3)смэв (3)infowatch (3)llama.cpp (3)llama (3)open-weight (3)HWiNFO (3)Mozilla Thunderbird (3)thunderbird (3)пароль (3)twitch (3)стримеры (3)кибермошенничество (3)игровые студии (3)sharepoint (3)аватары (3)контейнеры (3)12v-2x6 (3)vision pro (3)метрики (3)цена (3)lts (3)corsair (3)удаление данных (3)azure (3)ASML (3)counter strike (3)очки (3)хирургия (3)bim-проектирование (3)mfa (3)визуализация (3)родительский контроль (3)nano banana (3)QEMU (3)зарплаты (3)генерация текста (3)Wireshark (3)microsoft store (3)бэкапы (3)vercel (3)демис хассабис (3)мнение (3)accenture (3)портативные устройства (3)warner bros. (3)ubuntu 26.04 (3)переводчик (3)сим-карта (3)интернет вещей (3)трояны (3)грузовики (3)инфраструктура ии (3)волож (3)коннекторы (3)фонды (3)suno (3)музыкальная индустрия (3)беспилотные технологии (3)аэростаты (3)myrient (3)sdk (3)умные телевизоры (3)прокси (3)оценка работы (3)картографические сервисы (3)ставки (3)минобороны сша (3)меню (3)комиссия (3)управление продуктом (3)рви (3)техас (3)android 17 (3)приложения для android (3)русский язык (3)встреча (3)голосовые ассистенты (3)печать (3)Shorts (3)презентация (3)mlops (3)Qwen-3.5 (3)alibaba qwen (3)стандарты (3)монополия (3)настольные игры (3)тайвань (3)кража (3)планшет (3)парсинг (3)multifactor (3)байконур (3)космодром (3)восстановление (3)deepseek r2 (3)mamont (3)заражение (3)Gemini 3.1 Flash Lite (3)пользовательские данные (3)Duolingo (3)платные подписки (3)слежка (3)водород (3)ookla (3)игровой движок (3)вентиляторы (3)fraud protection (3)учетные данные (3)ноутбуки dell (3)ноутбуки 2025 (3)космонавты (3)рбпо (3)тестирование мобильных приложений (3)ноутбуки для бедных (3)OCR (3)будущее здесь (3)atomic heart (3)open ai (3)NWinfo (3)acp (3)keychron (3)антиспам (3)leakbase (3)Центробанк (3)кастомизация (3)спутниковое телевидение (3)нтв плюс (3)gartner (3)торговая марка (3)роспатент (3)сохранение данных (3)vk play (3)редакторы (3)переводы (3)модерация (3)инструмент (3)планировщик задач (3)it-администратор (3)новости технологий (3)конгресс сша (3)дашборды (3)YouTube Shorts (3)аккумулятор (3)Хабы (3)ит-соревнование (3)microsoft defender (3)антивирус (3)общение (3)расходы (3)пошлины (3)steam machine (3)ран (3)инди-игры (3)Google Research (3)Play Store (3)безопасность в ит (3)sony playstation (3)walmart (3)gemma (3)artificial analysis (3)ai overviews (3)партнеры (3)X (3)dmca (3)artemis (3)ценообразование (3)проверка кода (3)солнечная энергия (3)локальный ии (3)джек дорси (3)ит-тренды (3)Autodesk (3)писатели (3)копирайт (3)судебный запрет (3)даркнет (3)компенсации (3)copyright (3)AI-ассистенты (3)локальные модели (3)декомпиляция (3)дистрибутивы (3)дистрибутив linux (3)учебный процесс (3)оцифровка (3)EAP (3)Мастер отчетов (3)джейлбрейк (3)ffmpeg (3)nemoclaw (3)Иран (3)геймерская мышь (3)ботнет (3)nas (3)annas archive (3)видеотехника (3)метки (3)Sigil (3)curl (3)ceo (3)аварии (3)просмотр видео (3)инцидент-менеджмент (3)предиктивная диагностика (3)интеграции (3)галлюцинации (3)яндекс 360 (3)госулуги (3)ds (3)digg (3)перезагрузка (3)диски (3)cto (3)cio (3)steam deck (3)CPU-Z (3)инвестиции в стартапы (3)alexa+ (3)режимы (3)банкротство (3)генерация речи (3)портирование (3)IPv6 (3)экология (3)вакансии для аналитиков (3)день открытых дверей (3)arch linux (3)windows 11 24h2 (3)промпт-инжиниринг (3)jvm (3)пакеты (3)xbox one (3)лимиты (3)графика (3)genai-платформа (3)аутсорсинг (3)серверное администрирование (3)банк (3)лицензия (3)тимлиды (3)стратегия развития (3)Terafab (3)Vera Rubin (3)linux kernel (3)foxconn (3)служба поддержки (3)аудиосистемы (3)модификации (3)установка windows (3)настройка windows (3)предиктивная аналитика (3)bing (3)виртуальный сервер (3)http3 (3)gc (3)незаконный майнинг (3)gpt-5.4 mini (3)сколково (3)интерпол (3)powertoys (3)киберразведка (3)portal (3)высокая производительность (3)сетевой инженер (3)нативные приложения (3)сокращения штата (3)распознавание речи (3)enterprise AI (3)телефонная связь (3)авто.ру (3)сбп (3)чертежи (3)цоды (3)GNOME (3)Grok 4.20 (3)видеопамять (3)местоположение (3)вакансии работа (3)агентные модели (3)microsoft 365 copilot (3)корпоративные клиенты (3)LLM-агенты (3)аналитика данных (3)MiniMax M2.7 (3)Replit (3)аскон (3)компас-3d (3)компас3d (3)компас (3)Composer (3)3d (3)биткоин (3)криптокошельки (3)hermes (3)бренды (3)ретро-консоли (3)инклюзия (3)сферум (3)учителя (3)tsmc (3)VK WorkSpace (3)arxiv (3)научные работы (3)препринты (3)эмоции (3)cPanel (3)дарквеб (3)создание контента (3)нагрузочное тестирование (3)водители (3)радио (3)топливо (3)Яндекс Поиск (3)портирование игр (3)cms (3)Twitter (3)kandinsky (3)Baidu (3)darksword (3)android-разработка (3)дорожное движение (3)AEO (3)агенты ии (3)таймер (3)low-code платформы (3)connect (3)форумы (3)huggingface (3)сокращения персонала (3)командная строка (3)ндс (3)стажировка в it (3)Бюро 1440 (3)яндекс лавка (3)arxiv.org (3)автотесты (3)ERP (3)корпоративные коммуникации (3)торги (3)облачные хранилища (3)ald pro (3)pypi (3)провайдер (3)сервис (3)AnyDesk (3)Qt (3)гравитационные волны (3)реестр windows (3)отключение (3)Антиплагиат (3)ios 27 (3)macos 27 (3)игровая мышь (3)критическая инфраструктура (3)передача данных (3)перенос данных (3)социальная инженерия (3)инженерные системы (3)данные пользователей (3)self service (3)deepfake (3)концерты (3)bluetooth (3)синхронизация (3)наручные часы (3)генетика (3)intekey (3)почта (3)edge AI (3)tails 7 (3)яндекс музыка (3)прекращение продаж (3)моды (3)zx spectrum (3)симуляция (3)безопасный ии (3)экзамены (3)платформа виртуализации (3)basis dynamix (3)схд (3)рвб (3)фото (3)рынок (3)квантовые вычисления (3)карты памяти (3)rcs (3)видеозвонки (3)opus (3)Bluesky (3)Attie (3)домашние животные (3)сим-карты (3)трамп (3)kindle (3)сон (3)on-premise (3)университет (3)т1 (3)ниту мисис (3)температура (3)google drive (3)батарейки (3)домашний интернет (3)airbnb (3)квантовые технологии (3)crypto (3)аквариус (3)продвижение (3)proton (3)анимация (3)восстановленные устройства (3)реестр ПО (3)цифровая гигиена (3)sql (3)балансировщик (3)обоняние (3)утечки (3)магазины (3)электронные чернила (3)вымпелком (3)администрирование (3)yadro (3)ubisoft (3)инфотекс (3)протоколы (3)руководитель (3)заказы (3)зумеры (3)TBPN (3)кремниевая долина (3)туалет (3)Servo (3)касперская (3)обновление по (3)визионерство (3)италия (3)Euro-Office (3)QuickView (3)HWMonitor (3)ideco (3)AI-безопасность (3)курьер (3)обработка данных (3)торренты (3)игровые ноутбуки (3)экосистемы (3)рекомендательные системы (3)росэл (3)офисный софт (3)no-code решения (3)ai митап (3)SourceCraft (3)контроллер (3)дистанционное управление (3)дезинформация (3)waf (3)usergate waf (3)zero-day (3)nyt (3)wms (3)hr-технологии (3)Glow 26 (3)шумоподавление (3)право на ремонт (3)цодостроение (3)service desk (3)мультиагентные системы (3)google meet (3)мультимодальные модели (3)редакторы кода (3)инвентаризация (3)ек (3)европейский союз (3)Claude Sonnet (3)яндекс авто (3)apple intelligence (3)mac studio (3)маркетплейс цифровых товаров (3)маркетплейсы приложений (3)confluence (3)крипта в рф (3)unitree robotics (3)internet archive (3)реестр (3)платформы разработки (3)gopro (3)фишинговые атаки (3)птицы (3)rdp (3)автоматизация разработки (3)финансы и банковская сфера (3)surface (3)google photos (3)преподаватели (3)короткие видео (3)sdn (3)сотовые операторы (3)argus (3)криптобиржа (3)GPT-Rosalind (3)проверка личности (3)google фото (3)проверка паспорта (3)прошивка (3)цифровой двойник (3)claude design (3).su (3)контроллер домена (3)полигон (3)чёрные дыры (3)обработка видео (3)потребление воды (3)архитектура систем (3)зарядная станция (3)инициатива (3)дропперство (3)gpt image 2 (3)Windows Defender (3)управление устройствами (3)прогноз (3)страховка (3)удалённый доступ (3)язык программирования (3)ретро-гейминг (3)молекулярная биология (3)Мира Мурати (3)клиентский сервис (3)godot (3)игровые движки (3)мобильные игры (3)научные исследования (3)сброс пароля (3)доменные зоны (3)национальная безопасность (3)запрещенная информация (3)noctua (3)swg-система (3)облачный гейминг (3)canonical (3)нефтегаз (3)дополненная реальность (3)платформа разработки (3)хассабис (3)truecaller (3)маршрутизация (3)параллельный импорт (3)av2 (3)бум ии (3)виджеты (3)беспилотники (3)троян (3)прозрачность (3)рендеринг (3)маск (3)отключение интернета (3)нативная разработка (3)масштабирование (3)vLLM (3)резервирование (3)акселератор (3)колонки (3)динамики (3)фитнес-трекеры (3)fitbit air (3)грант (3)shinyhunters (3)найм персонала (3)форки (3)rpcs3 (3)ии-слоп (3)bettermediainfo (3)general motors (3)Gemini Omni (3)электросамокаты (3)мероприятие (3)какработаетмозг (3)забастовка (3)облачный сервер (3)компьютерная мышь (3)starship (3)малый бизнес (3)supply chain (3)кнопка (3)религия (3)уязвимости нулевого дня (3)кофе (3)газпромбанк (3)Universal Music Group (3)коммиты (3)it-аккредитация (3)отключение серверов (3)inference (3)Nemotron 3 Ultra (3)rtx spark (3)импортозамещение по (3)fable 5 (3)Claude Mythos 5 (3)crowdstrike (2)stop killing games (2)сталкинг (2)вставка изображений (2)орбита (2)ssa (2)vlm (2)дрон (2)цифровая валюта (2)растения (2)смена руководства (2)Trayy (2)психоз (2)windows xp (2)компьютерная техника (2)privacy display (2)antigravity (2)журнал (2)светодиоды (2)цепочки поставок (2)отставки и назначения (2)ии-контент (2)графические редакторы (2)NetSpeedTray (2)снижение цен (2)bigdata (2)Moonshot (2)MISRA C 2023 (2)парковки (2)прогноз погоды (2)экономия (2)большой адронный коллайдер (2)коллайдеры (2)эффективность (2)ldm (2)GraphQL (2)хранилище (2)indus (2)sarvam (2)гарант (2)bothub (2)GPT-4o (2)аренда серверов (2)форензика (2)инфобез (2)судебная практика (2)дома (2)опухоли (2)visual studio code (2)аэротакси (2)шум (2)учетная запись (2)карманный компьютер (2)веб-версия (2)репозиторий (2)стримы (2)paypal (2)blizzard (2)скриншоты (2)youtube premium lite (2)sonnet 4.6 (2)голосовые помощники (2)колонка (2)аниме (2)ссылки (2)тайконавты (2)космические корабли (2)космический мусор (2)фотоника (2)tmp (2)textmeshpro (2)text (2)джуны (2)бразилия (2)биотех (2)технологии будущего (2)агротех (2)устойчивое развитие (2)1password (2)Clonezilla Live (2)AIDA64 (2)boeing (2)телеметрия (2)нло (2)имена (2)случайность (2)энтропия (2)next.js (2)удаленное выполнение кода (2)соискатели (2)операционная система (2)diy-компьютер (2)счетная палата (2)электронные таблицы (2)база данных (2)партнерская программа (2)hyperos (2)мфу (2)международная космическая станция (2)антимонопольное расследование (2)оптоволоконный кабель (2)Wayve (2)онлайн-казино (2)лутбоксы (2)axiom (2)mustang (2)ОАЭ (2)Cortical Labs (2)астронавты (2)crew dragon (2)gemini 3 flash (2)аутентификация пользователей (2)observability (2)Firefly (2)ии музыка (2)SynthID (2)nano banana pro (2)специалисты (2)Toyota (2)smola games (2)русы против ящеров (2)мурзавод (2)compresso (2)корпус (2)Morningstar (2)cash app (2)entra (2)субд tantor (2)беспроводная зарядка (2)qi2 (2)sudo (2)google translate (2)перевод (2)гринатом (2)мосбиржа (2)мексика (2)ФСТЭК 117 (2)vivo (2)магнитное поле (2)Project Prometheus (2)Джефф Безос (2)porsche (2)elegoo (2)космические компьютеры (2)микросхемы (2)ИИ-технологии (2)мощность (2)рабочий код (2)гранты (2)Perplexity Computer (2)ассистенты (2)производство электроники (2)инцидент (2)press f (2)открытое письмо (2)артемида-3 (2)высадка на луну (2)скрипты (2)настройка (2)Carter54 (2)sora 2 (2)grok imagine (2)google maps (2)инсайдеры (2)Alikson Group (2)онлайн-курсы (2)компьютерные игры (2)ретрогейминг (2)рубин (2)звёзды (2)андрей карпаты (2)таможня (2)посылки (2)windows 365 (2)Shotcut 26 (2)Shotcut (2)компьютерные клубы (2)моделирование (2)gemini 3 pro (2)chatgpt 5.2 (2)Segra (2)revolut (2)h200 (2)Союзмультфильм (2)копирование (2)gif (2)стикеры (2)голосование (2)cd (2)русификация (2)бренд (2)бигтех (2)снимок экрана (2)ножницы (2)возврат (2)амортизация (2)повышение производительности (2)grapheneos (2)amd ryzen (2)геоинформационные сервисы (2)обзвоны (2)qa management (2)qa образование (2)исследования в ит (2)bmw (2)test it (2)древний рим (2)встречи (2)дефект (2)hyprland (2)Armbian 26 (2)Armbian (2)voice mode (2)голосовой ввод (2)модули памяти (2)ledger (2)холодное хранилище (2)кредитование (2)мвидео отдыхает (2)планшетный компьютер (2)планшетник (2)домен (2)доменная зона (2)nfc (2)uwb (2)скрейпинг (2)InfoWatch Traffic Monitor (2)gigachat enterprise (2)сод (2)тестирование приложений (2)luma (2)m5 (2)criteo (2)голосовой режим (2)GPT-5.3 (2)ray-ban (2)ray-ban meta (2)devsecops -инженеры (2)seagate (2)гонконг (2)издатели (2)драйвер (2)защита от ботов (2)find hub (2)ethernet (2)сетевые подключения (2)игровые мониторы (2)corning (2)oauth (2)mac os x (2)machinelearning (2)шины (2)адаптивность (2)цифровые технологии (2)сатья наделла (2)cloud imperium games (2)star citizen (2)micron (2)scada (2)геймификация (2)продуктовая разработка (2)qa engineer (2)тестирование по (2)тестировщик (2)анализ данных (2)skills (2)mundfish (2)agentic coding (2)Nitrux (2)oukitel (2)outlook.com (2)почтовые сервисы (2)электронные письма (2)Nothing (2)abc анализ (2)fmr (2)склады (2)регистрация (2)HMD (2)триколор (2)финансовые данные (2)ansible (2)rtx 3060 (2)пуши (2)project management (2)веб-страницы (2)защита персональных данных (2)Apache Kafka (2)фармацевтика (2)фарма (2)думскроллинг (2)project helix (2)дороги (2)женщины (2)united airlines (2)авиаперелеты (2)групповые политики (2)идентификаторы (2)регистраторы доменов (2)нейронные сети (2)сокращение штата (2)Marvell Technology (2)ASIC (2)яндекс электро (2)зарядные станции (2)навыки (2)мотивация (2)орбитальные станции (2)космические станции (2)сенат сша (2)Galaxy Z Trifold (2)sminex (2)bim-моделирование (2)девелопмент (2)RustDesk (2)смена оператора (2)еврокомиссия (2)odf (2)редизайн интерфейса (2)oura (2)умное кольцо (2)презентации (2)редактирование изображений (2)Linux From Scratch (2)erp-системы (2)молодые ученые (2)инди-разработка (2)AI-исследования (2)AI-модели (2)облачные платформы (2)рак (2)городская инфраструктура (2)Янн ЛеКун (2)Uni-1 (2)Qwen3 (2)распродажи (2)vizio (2)AI-чатботы (2)британия (2)nvidia h200 (2)AI-дата-центры (2)Insilico Medicine (2)обновления безопасности (2)digiKam (2)node.js (2)Elon Musk (2)патентные тролли (2)grammarly (2)superhuman (2)копирайтинг (2)gsma (2)галактики (2)спектр (2)росстандарт (2)эмуляция (2)coding agents (2)HPE (2)HandBrake (2)electronic arts (2)nanochat (2)железная дорога (2)переезд (2)авария (2)доклады (2)генеративные модели (2)багхантинг (2)резервные копии (2)xbox 360 (2)антивирусная защита (2)цифровой ликбез (2)ГОСТ VPN (2)InfoWatch ARMA Industrial Firewall (2)сплав (2)dba (2)НИИТМ (2)лаборатория (2)многоцветная печать (2)цветная печать (2)AI-стартапы (2)remote desktop (2)центр обработки данных (2)продажа бизнеса (2)тесты производительности (2)бонусы (2)фит (2)qr (2)сжатие данных (2)Яндекс Браузер (2)локальный запуск нейросетей (2)Health AI (2)цифровая медицина (2)One Medical (2)павел дуров (2)apple ii (2)innersloth (2)among us (2)локализация (2)информационные системы (2)учебный процесс в it (2)baas (2)днк (2)Яндекс Такси (2)мобильный гейминг (2)data (2)amd epyc (2)децентрализованные сети (2)ATS (2)zendesk (2)работа с клиентами (2)налоговые льготы (2)зарплаты в it (2)станция (2)Erlang (2)idp (2)диасофт (2)экспертиза (2)зерокодинг (2)нижний новгород (2)devrel (2)яндекс маркет (2)режим xbox (2)микрон (2)регионы (2)релокация (2)удалёнка (2)рынок ит (2)wordle (2)головоломки (2)логические игры (2)страхование (2)нехватка (2)lovable (2)бюджет (2)dcimanager (2)сети (2)обзор (2)игрушки (2)фильтрация (2)framework (2)Kitty (2)PeerTube 8 (2)PeerTube (2)знакомства (2)генеральный директор (2)перебои (2)телевидение (2)каналы (2)niantic (2)обход аутентификации (2)сервис-партнер (2)комплексный сервис (2)сервисная поддержка (2)управление инфраструктурой (2)анализ рисков (2)GTD (2)баг-баунти (2)вознаграждения (2)медицинский бренд (2)смарт-очки (2)игры для программистов (2)антарктида (2)телескоп (2)Calibre 9 (2)поисковые технологии (2)обмен ссылками (2)облачное хранение данных (2)вредоносные игры (2)ограничение (2)Стивен Спилберг (2)UMO (2)антропоморфные роботы (2)навигация (2)Palantir (2)Logitech Options+ (2)Claude лимиты (2)автономная работа (2)обработка текста (2)системы ии (2)codewall (2)велосипед (2)скорость (2)генеративный AI (2)плейлисты (2)Seedance 2.0 (2)OpenTTD (2)Debian 13 (2)метаданные (2)работа с данными (2)windows server 2025 (2)дистрибутивы linux (2)смарт-часы (2)Agent SDK (2)фонд свободного по (2)fsf (2)частота обновления (2)отели (2)тестирование игр (2)asrock (2)ddr4 (2)правительство (2)ram (2)gdc (2)игровая консоль (2)gaming copilot (2)hr-tech (2)заказная разработка (2)delta design (2)семинары (2)проектирование электроники (2)питер штайнбергер (2)airpods (2)правительство рф (2)персональный ассистент (2)merriam-webster (2)тест тьюринга (2)беспилотный транспорт (2)практика (2)статический анализ кода (2)gtc 2026 (2)физический ии (2)взрослый контент (2)хактивисты (2)исследования и прогнозы в it (2)возврат денег (2)датчики (2)текстовый редактор (2)звуковая карта (2)видеоредактор (2)прогнозы (2)коммунальные услуги (2)промостраницы (2)электромотоциклы (2)oobe (2)онлайн-покупки (2)аренда сервера (2)starcloud (2)aot (2)spring framework (2)gpt-5.4 nano (2)киты (2)3d-объекты (2)Blackwell (2)byd (2)Linux Foundation (2)вакансия (2)радиация (2)преступность (2)PT Fusion (2)ioc (2)десктопные приложения (2)стриминг музыки (2)s26 ultra (2)разрешение (2)настольный компьютер (2)сетевое администрирование (2)инфраструктурные решения (2)ржд (2)speech-to-text (2)заметки (2)ifixit (2)телефония (2)кодинг-агент (2)LLM-бенчмарки (2)код спорта (2)OLED (2)cybercrime (2)GNOME 50 (2)санкт-петербург (2)м.видео-эльдорадо (2)компьютеры тренды (2)компоненты (2)перемещение (2)работа в команде (2)google поиск (2)chromium (2)улучшения (2)Hunter Alpha (2)MiMo-V2-Pro (2)базовый доход (2)dwh (2)киберпреступники (2)логотипы (2)chuwi (2)termidesk (2)кейс (2)компас-3d home (2)Qwen3.5 (2)LiTo (2)Samba (2)Яндекс Погода (2)калькуляторы (2)telegram bot (2)веб-краулер (2)суперприложения (2)doordash (2)нейрослоп (2)кодинг-агенты (2)data collection (2)жилье (2)мобильность (2)автономность (2)РСЯ (2)физлица (2)ИП (2)инклюзия в цифровых продуктах (2)срк (2)ии-серверы (2)контрабанда (2)ai studio (2)психология (2)Plesk (2)Unitree G1 (2)киберпреступления (2)KiCad (2)веб-хостинг (2)высоконагруженные проекты (2)вождение (2)съемные батареи (2)joy-con (2)нгту (2)cbs (2)радиостанция (2)радиовещание (2)Strava (2)автоваз (2)lada (2)аренда (2)docsascode (2)docs (2)проекты (2)кения (2)суда (2)судоходство (2)ElevenLabs (2)маркетплейс музыки (2)союз (2)решение задач (2)AI токены (2)compute (2)WeChat (2)сборы (2)атмосфера (2)уэбб (2)МГТУ им. Н.Э. Баумана (2)Ghostty (2)coruna (2)airdrop (2)развитие (2)лекарства (2)исследователи (2)модульность (2)эволюция (2)npm-пакет (2)атака на цепочку поставок (2)педагогам (2)поиск информации (2)цукерберг (2)джони айв (2)банкоматы (2)Agile (2)м (2)Atlas 350 (2)ии-системы (2)Ascend 950PR (2)Ascend (2)ripgrep (2)regex (2)wwdc 2026 (2)iphone 17 pro (2)DOW (2)роботы-курьеры (2)панель задач (2)windows insider (2)apple maps (2)библиотека (2)ml-модели (2)ИИ в образовании (2)Kodik (2)АрхиТех ИИ (2)ИИ в бизнесе (2)CRM (2)интернет-банк (2)прототип (2)аукцион (2)рободоставка (2)kimwolf (2)Яндекс Реклама (2)обработка фотографий (2)astra configuration manager (2)гибридная инфраструктура (2)рекламный рынок (2)supply chain attack (2)teampcp (2)credentials (2)ботнеты (2)бесплатно (2)покрытие (2)сенсорные экраны (2)артисты (2)подтверждение (2)лунная база (2)категорирование (2)преступления (2)законы (2)дистрибутив (2)пентестинг (2)terraform (2)tantor platform (2)платформа тантор (2)инженерная инфраструктура (2)демо (2)запас хода (2)ARC-AGI-3 (2)питание (2)рентген (2)Белый дом (2)защита детей (2)песни (2)зависимость (2)лейблы (2)sennheiser (2)капча (2)видеохостинг (2)fm (2)tcp (2)доктор веб (2)dr.web (2)Amplicode (2)брокер сетевых пакетов (2)цб рф (2)рабочие станции (2)seiko (2)нейробиология (2)разработка лекарств (2)honda (2)развитие бизнеса (2)кейсы (2)креатив (2)менеджмент продукта (2)доступность (2)финансовые отчеты (2)гарантия (2)text-to-speech (2)корпоративное по (2)сравнение (2)CopyQ (2)DietPi (2)e-mail (2)modding (2)модификация (2)реструктуризация бизнеса (2)рекламная сеть (2)браузерные игры (2)mermaid (2)nintendo switch 2 (2)физические носители (2)цифровые копии (2)виртуальные машины (2)дубна (2)языки (2)термины (2)хаббловская напряжённость (2)Hark (2)Figure AI (2)gigacode (2)stanford (2)этика ии (2)платная подписка (2)премиум-подписки (2)pqc (2)постквантовое шифрование (2)квантовые алгоритмы (2)голос (2)гравитация (2)sd (2)claudecode (2)аудит (2)av1 (2)кодеки (2)ai security (2)багбаунти (2)шпионское ПО (2)спортивное программирование (2)рспп (2)электродвигатель (2)dlp (2)purview (2)sim (2)пенсионеры (2)вишинг (2)солнечные батареи (2)видеоигры и их развитие (2)картриджи (2)altera (2)серверные процессоры (2)стив джобс (2)AIaaS (2)банки.ру (2)трансформация (2)инструменты мониторинга (2)битрикс24 (2)1с-битрикс (2)курс (2)симуляторы (2)грузовик (2)мгу (2)мегафон (2)arenadata (2)carprice (2)александр галицкий (2)маи (2)биомедицина (2)озп (2)LiteLLM атака PyPI (2)уведомление (2)всош (2)telegrambot (2)сканирование (2)программы-вымогатели (2)ios 26 (2)переработки (2)коммутатор (2)технологические компании (2)медные линии (2)отраслевые решения (2)it-решения (2)удаленное подключение (2)basis workplace (2)виртуальные рабочие столы (2)apple store (2)убытки (2)роботы-гуманоиды (2)имя пользователя (2)email (2)joomla 6 (2)релиз безопасности (2)облачные провайдеры (2)слова (2)1 апреля (2)суверенитет (2)capex (2)беспроводные клавиатуры (2)apollo go (2)восстановленная техника (2)изолированный контур (2)RPA (2)документооборот (2)ЭДО (2)совместимость (2)ускорители (2)Salesforce (2)axios (2)js (2)hr-бренд (2)ракетостроение (2)подарочные карты (2)rspamd (2)Экспресс-АТ1 (2)спутниковое вещание (2)ГКРЧ (2)швабе (2)esim (2)GLM-5V-Turbo (2)piter-ix (2)торговые марки (2)платежи онлайн (2)аудит иб (2)аудит иб-инфраструктуры (2)запахи (2)мошенники в интернете (2)определитель номера (2)звонки на мобильный (2)психологическая безопасность (2)superjob (2)корпоративные системы (2)ии-поиск (2)управление доступом (2)RISC-V (2)shutterstock (2)ранний доступ (2)агентный AI (2)бег (2)академическая честность (2)microsoft ai (2)h-1b (2)баннеры (2)тимлиды и разработчики (2)регуляторика (2)нью-йорк (2)бумажные книги (2)чтение (2)AI policy (2)amazon leo (2)usb-c (2)void (2)земля (2)UBTech (2)embodied ai (2)fujitsu (2)Qmmp (2)обмен сообщениями (2)город (2)ppem (2)администрирование бд (2)ciso (2)LTE (2)бухгалтерия (2)Артемида II (2)zVirt (2)англия (2)бакалавриат (2)кэдо (2)PeaZip 11 (2)PeaZip (2)i486 (2)Phosh (2)транскрибация (2)лояльность (2)NLP (2)киберучения (2)standoff (2)сценарии атак (2)розничная торговля (2)ctf (2)hr-процесс (2)публичное облако (2)продажа данных (2)тенденции (2)изменения в законодательстве (2)законодательство и it-бизнес (2)риски (2)нейронный рендеринг (2)промты (2)стандарт (2)регламент (2)agplv3 (2)оптимизация кода (2)open source LLM (2)большая четверка (2)фанаты (2)zero-day уязвимости (2)OpenBSD (2)автоматизация тестирования (2)креативность (2)право (2)вакансии в ит (2)привилегированные учетные записи (2)innostage pam (2)golem (2)AI automation (2)магазин (2)аудиокниги (2)конструкторы (2)слепота (2)инструкции (2)энтузиасты (2)mobile (2)промышленный шпионаж (2)RTX 4090 (2)теневой рынок (2)ps1 (2)hdmi (2)kindle fire (2)электронные книги (2)серверное оборудование (2)видеосервис (2)sony music (2)warner music (2)отчёты об ошибках (2)oracle database (2)tantor polar (2)импорт (2)комиссии (2)ии-обзоры (2)wcs (2)роботизация производства (2)Muse Spark (2)датасеты (2)anc (2)конфиденциальные данные (2)Poke (2)imessage (2)Liquid AI (2)Tubi (2)медиасервисы (2)цифровой суверенитет (2)btc (2)облачный провайдер (2)найм разработчиков (2)спутники связи (2)молодежь (2)iphone air (2)iphone 18 (2)intellijidea (2)вайб-программирование (2)корпоративная сеть (2)целевые атаки (2)сельское хозяйство (2)нспк (2)инн (2)роса мобайл (2)mobile inform group (2)нтц ит роса (2)Shutter Encoder (2)notebooklm (2)android xr (2)гарнитуры (2)расширения (2)переписка (2)ice (2)GPT-4 (2)видеоаналитика (2)привилегированный доступ (2)финтех-проекты (2)Международные космические игры (2)ноутбуки 2026 (2)продление поддержки (2)прибыль (2)mozilla firefox (2)европейская комиссия (2)монополизм (2)0-day (2)acrobat reader (2)Anthropic API (2)microsoft word (2)faa (2)powershell (2)andon labs (2)windows terminal (2)видеохостинги (2)мейнтейнеры (2)робособака (2)tiobe (2)plex (2)чешский язык (2)экран блокировки (2)игромир (2)маркетплейс плагинов (2)регуляторы (2)переименование (2)высокопроизводительные вычисления (2)chatgpt plus (2)прослушка (2)jmix (2)новости криптовалюты (2)криптоообменники (2)криптовалюта и закон (2)cryptocurrency (2)crypto news (2)складские процессы (2)логистика склада (2)gif-анимация (2)баскетбол (2)аналитик (2)fullstack (2)тренажёр (2)1с-разработка (2)мемристор (2)сгенерированный контент (2)экшн-камеры (2)видеосъемка (2)среда обитания (2)акустика (2)мемы (2)игровая индустрия (2)yandex b2b tech (2)hiro (2)вэб (2)герпес (2)геймджем (2)платежные карты (2)ibp (2)канбан-доска (2)чек-листы (2)планировщик для команды (2)делегирование задач (2)нативное приложение (2)warp (2)распознавание изображений (2)csharp (2)snap (2)асинхронные коммуникации (2)MWS TeamStream (2)asana (2)umg (2)наем (2)windows 8 (2)scada системы (2)redteam (2)standoff 365 (2)движения (2)федеральный суд (2)адвокаты (2)синтез речи (2)поезда (2)хуавей (2)Grinex (2)взлома (2)вредоносное программное обеспечение (2)нкцки (2)Thunderbolt (2)cpython (2)nac (2)организации (2)опрос сотрудников (2)социальное взаимодействие (2)социология (2)kafka (2)фотоны (2)инфракрасное излучение (2)gitea (2)forgejo (2)приговор (2)chatgpt 5.4 (2)lsass (2)циклическая перезагрузка (2)memory (2)world (2)nist (2)критерии (2)пнипу (2)2d (2)Grok 4.30 (2)imei (2)рейтинг рунета (2)невада (2)identity and access management (2)identity (2)401 unauthorized (2)brave (2)новости финансов (2)аркадные автоматы (2)Inventorus (2)тим кук (2)KillerPDF (2)ants (2)stem (2)Recursive Superintelligence (2)подсветка (2)Zig (2)краудфандинг (2)pirate bay (2)сериалы (2)дроппер (2)ssh (2)serverless (2)itsm365 (2)Insta360 (2)GPT Images 2 (2)мод (2)rds (2)критическая уязвимость (2)rwb (2)цп (2)Bronze Games (2)безопасная инфраструктура (2)дропперы (2)xbox mode (2)pixel 10 (2)character.ai (2)ролевые игры (2)копилефт (2)google sheets (2)google docs (2)аэропорты (2)polymarket (2)токенмаскинг (2)бизнес-модели (2)id software (2)кнопки (2)политики (2)прогнозы в ит (2)kaspersky (2)автоматическая генерация кода (2)венчур (2)анализ сетевого трафика (2)nta-системы (2)pt nad positive technologies (2)брокеры сетевых пакетов (2)зеркалирование трафика (2)дедупликация (2)ответвители сетевого трафика (2)оптимизация сетевого трафика (2)chatgpt-5.5 (2)длинный контекст (2)cxmt (2)экосистема (2)широкополосный доступ (2)донаты (2)godaddy (2)дарио амодеи (2)bambu studio (2)orca slicer (2)FreeRDP (2)фнс россии (2)коллекционирование (2)роутер (2)безопасность данных (2)proton pass (2)ssh-agent (2)Sonnet (2)windows update (2)журналистика (2)тексты (2)кот (2)компьютерные мыши (2)Redmi (2)домашние роутеры (2)стена (2)складные смартфоны (2)групповая политика (2)промпты (2)R-Vision SIEM (2)жидкостное охлаждение (2)robotaxi (2)mediatek (2)iphone fold (2)ложь (2)AI Credits (2)GitHub Actions (2)нейроюрист (2)импортонезависимость (2)uc (2)совместная работа (2)подделки (2)VLA (2)СОРМ (2)whoosh (2)мобильный трафик (2)drm (2)uem (2)Fedora Linux 44 (2)митапы по фронтенду (2)системная интеграция (2)ableton (2)творческие профессии (2)ztna (2)llm-attack (2)vmware (2)advanced packaging (2)apple vision pro (2)Copy Fail (2)playstation 4 (2)dos (2)медицинский ии (2)временные ряды (2)опенсорс (2)виртуальные рабочие места (2)тренировки (2)Карпатый (2)Digital Q.Database (2)удалённое управление (2)союз-5 (2)кулеры (2)link (2)foundation models (2)ARI (2)Assured Robot Intelligence (2)судебные документы (2)фотокамеры (2)gamestop (2)радиосвязь (2)хакер (2)videolan (2)декодер (2)dav1d (2)дискуссии (2)rtx 5090 (2)бпла (2)сделай сам (2)хуанг (2)коллективный иск (2)системный блок (2)switch (2)nokia (2)rufus (2)nhs (2)втб (2)пожары (2)возгорания (2)маркус (2)mercedes-benz (2)переключатели (2)встраиваемые системы (2)embedded (2)рецензирование (2)spotify premium (2)ОВО (2)название (2)локальные нейросети (2)финансовый отчет (2)круглый стол (2)hr в it (2)ai-разработка (2)трассировка лучей (2)протезы (2)профсоюз (2)магнитные поля (2)ртк-цод (2)кинематограф (2)безопасность веб-приложений (2)Multi-agent системы (2)HiClaw (2)Alibaba Cloud (2)AI-оркестрато (2)speculative decoding (2)inference speed (2)локальный запуск (2)SubQ (2)sparse attention (2)DAEMON Tools (2)бэкдор (2)айтишники (2)кадровые перестановки (2)стихийные бедствия (2)dos-атаки (2)ask.com (2)операторы (2)нефтегазовая отрасль (2)узбекистан (2)кибершпионаж (2)lpe (2)Dirty Frag (2)тэк (2)fitbit (2)google health (2)фитнес-браслеты (2)кинопроизводство (2)актеры (2)номинации (2)Брайан Чески (2)ds proxima (2)отказоустойчивый кластер (2)высокая доступность (2)цифровизация промышленности (2)zara (2)видеокамеры (2)canon (2)яндекс диск (2)thinkpad (2)PHP (2)трудовое законодательство (2)путешествия (2)gm (2)фрод (2)METR (2)ретейл (2)электронный документооборот (2)ритейлеры (2)автопром (2)печатные платы (2)управление вниманием (2)llmops (2)подмосковье (2)Gemini Intelligence (2)хранилища данных (2)филамент (2)пластик (2)g42 (2)chromebook (2)агентное кодирование (2)RevPDF (2)затопление (2)белые хакеры (2)управление проектами и командой (2)контрафактная продукция (2)правила дорожного движения (2)nv energy (2)рабочие процессы (2)tanstack (2)астралинукс (2)юмор (2)Битрикс (2)отечественные решения (2)частная космонавтика (2)mvp (2)митапы в петербурге (2)проджект-менеджмент (2)водородное топливо (2)kioxia (2)Газпром (2)стипендии (2)виртуальное государство (2)Робот-доставщик (2)исследователи безопасности (2)встреча разработчиков (2)data engineering (2)инструменты разработки (2)электродвигатели (2)генерация текстов (2)Composer 2.5 (2)creality (2)stainless (2)forward-deployed engineer (2)ии-функции (2)масштабируемость (2)The.Hosting (2)Emmi AI (2)industrial AI (2)промышленный ИИ (2)бауманка (2)gemini spark (2)полноразмерные наушники (2)информатика (2)вычислительные мощности (2)сеченовский университет (2)наталья касперская (2)microsoft azure (2)переаккредитация (2)форматы (2)пинбол (2)no-code (2)no-code platform (2)mws ai (2)Qwen-3.7-Max (2)Qwen3.7-Max (2)cursor composer 2.5 (2)ремиксы (2)Ardour 9 (2)Ardour (2)кофейня (2)startup village (2)google pixel (2)система помощи водителю (2)adas (2)mastercard (2)ip-адрес (2)ps4 (2)Reuters (2)вуз (2)вознаграждение (2)баг (2)epyc (2)DeepSWE (2)duckduckgo (2)мобильный таск-менеджер (2)j (2)Dropbox (2)Дрю Хьюстон (2)Alphabet (2)highload (2)траспорт (2)gigabyte (2)вычислительная техника (2)паркинг (2)DNS-AID (2)code generation (2)Dynamic Workflows (2)тяжёлые ракеты (2)взрыв (2)ITAM (2)папа римский (2)markdown (2)минобрнауки (2)acer (2)оон (2)декодирование видео (2)сопровождение по (2)награды (2)мчс (2)выпускники (2)ИТ-соревнования (2)nta (2)доступность сайта (2)IntelliJ Platform (2)MAI-Thinking-1 (2)отечественный софт (2)imap (2)smtp (2)техсбор (2)Gemma 4 12B (2)nintendo switch (2)хранение энергии (2)ptai (2)rce (2)мерч (2)FrontierCode (2)SSL (2)обновление прошивки (2)Mythos 5 (2)облачные серверы (2)peoplesoft (2)MiMo Code (2)Adblock (2)galaxy ai (1)ИИ-система (1)sonic (1)sonic the hedgehog (1)sega forever (1)нпо (1)права потребителей (1)windows hello (1)преследование (1)отношения (1)южная америка (1)america-india connect (1)stargaze (1)столкновения (1)Just the Browser (1)Wine 11.3 (1)hipthreads (1)многопоточность (1)визуально-языковые модели (1)CacheOverflow (1)camar (1)трекер задач (1)сдвг (1)дислексия (1)синдром дефицита внимания (1)материал (1)вшэ (1)bugcrowd (1)исследование иб (1)bug bounty-программа (1)элеткромобиль (1)электрокроссовер (1)москвич (1)copilot advisors (1)notebooklm audio overviews (1)qr-код (1)хранение информации (1)tu wien (1)реферальная программа (1)спенсер (1)Trayy 3.0 (1)deepseek v3 (1)DeepRare (1)it-стандарты (1)форматы файлов (1)заставки (1)безмятежность (1)рабочий стол (1)Nanobot (1)Nanoclaw (1)рынок ИИ (1)ИИ-сервера (1)Winslop 0.6 (1)затемнение (1)диспей (1)kiro (1)bci (1)tetris (1)red bull (1)бумага (1)головоломка (1)rgb (1)гибкая плата (1)мти (1)печать деталей (1)fosdem (1)реестры (1)боли в руке (1)эргономика (1)туннельный синдром (1)работа за компьютером (1)упражнения для дома (1)здоровье гика (1)здоровье и компьютер (1)code.org (1)некоммерческие организации (1)компьютерные науки (1)amc (1)кинотеатры (1)мультфильмы (1)paint (1)Weston 15.0 (1)Weston (1)NetSpeedTray 1.2.5 (1)zclaw (1)archive.today (1)openai api (1)дата-аналитика (1)opensourse (1)кража AI моделей (1)китайские AI лаборатории (1)SWE-bench Verified (1)контаминация (1)AI кодинг (1)тестирование моделей (1)SWE-bench Pro (1)tat (1)атлантический океан (1)демонтаж (1)версия для пк (1)курсор мыши (1)отправка сообщений (1)групповые чаты (1)торвальдс (1)GitHub Secure Open Source Fund (1)LyX 2.5.0 (1)lyx (1)Lakka 6.1 (1)Lakka (1)spothero (1)Firefox 148.0 (1)дистилляция (1)talos linux (1)platform (1)nvidia blackwell (1)приложение погоды (1)школа авторов vk (1)физика частиц (1)простой (1)конструктор приложений (1)archivelink (1)техногиганты (1)энергосистема (1)pgconf (1)pgconf.спб (1)тестовые задания (1)отсев кандидатов (1)ментальное здоровье (1)skyworth (1)LSP (1)king of meat (1)glowmade (1)amazon games (1)платформеры (1)кооперативные игры (1)2026 (1)gsoc (1)google summer of code (1)gsoc2026 (1)ai-инструменты (1)бесплатное образование (1)бесплатное обучение (1)mango ai (1)cavalry (1)23 февраля (1)avitotech (1)лото (1)google play protect (1)вредоносные приложения (1)латвия (1)санкции евросоюза (1)3d-печать домов (1)недвижимость (1)ring (1)скрейперы (1)serpapi (1)musicbrainz (1)metabrainz (1)жизнь (1)афазия (1)Cobol (1)vr-гарнитура (1)элт (1)элт монитор (1)источники питания (1)бактерии (1)Qwen 3.5 Medium (1)редактор кода (1)воздушное такси (1)звуки (1)раздражители (1)города (1)HWiNFO 8.42 (1)GNU Octave 11 (1)GNU Octave (1)Mozilla Thunderbird 148 (1)FoodTruck Bench (1)harness engineering (1)новое устройство (1)alder lake (1)security (1)tassos (1)релизы безопасности (1)libreoffice online (1)collabora (1)открытый софт (1)возобновление работы (1)стриминговые платформы (1)нарушения (1)infowatch arma management console (1)infowatch arma стена (1)биг дата (1)обзвон (1)игровые платформы (1)DietPi 10.1 (1)Цифровое ID (1)world of warcraft (1)world of warcraft midnight (1)postgresql 18 (1)premium lite (1)скачивание видео (1)фоновое воспроизведение (1)haiku 4.5 (1)кипр (1)разработчики игр (1)ассоциация (1)wargaming (1)owlcat games (1)my.games (1)google tv (1)liquid death (1)урна (1)беспроводные колонки (1)патенты сша (1)аккумуляторы повышенной емкости (1)dara (1)онлайн-школы (1)Docker Compose (1)anti-ddos (1)NETworkManager 2026.2.22.0 (1)NETworkManager (1)Шэньчжоу-20 (1)китайская космонавтика (1)Google Classroom (1)педагогика (1)джира (1)dow jones (1)zyxel (1)Swift System Metrics (1)микрофлюидика (1)биоинформатика (1)alphago (1)Ineffable Intelligence (1)Clonezilla Live 3.3.1-35 (1)AIDA64 8.25 (1)AIDA64 8 (1)Bcachefs (1)Оверстрит (1)ProofOfConcept (1)когнитивные функции (1)пластичность мозга (1)MediaGoblin 0.15.0 (1)MediaGoblin (1)drop (1)приставки (1)отслеживание спутников (1)бям (1)цру (1)финансовые итоги 2025 (1)тестовое задание (1)bitbucket (1)работники (1)оценка производительности (1)импортозамещение ит-технологий (1)galaxy s20 fe (1)старое железо (1)церемония (1)braze (1)рассылка (1)кросс-компиляция (1)распределенные системы (1)milvus (1)траты (1)запрет иностранных слов (1)англицизмы (1)самртфоны (1)meizu (1)meizu 23 (1)продакт-менеджеры (1)tecno (1)модульные смартфоны (1)EUV (1)Ситуация 8 марта (1)автономное вождение iv уровня (1)азартные игры (1)team fortress (1)fdm-1 (1)Standard Intelligence (1)mustang mach-e (1)mach-e (1)багажник (1)meta ray-ban (1)Joby Aviation (1)Дубай (1)CL1 (1)биологический компьютер (1)цифровая информационная модель (1)единая платформа (1)информационное моделирование зданий (1)игженерия (1)архиектура (1)конструкции (1)потанин (1)Pika Labs (1)AI-генераторы видео (1)Pika AI Selves (1)генератор цифровых двойников (1)персональные двойники (1)crew-11 (1)MWS Tables (1)таблицы (1)SYNERGETIC (1)Reve (1)text-to-image-модель (1)v1.5 (1)разрешение 4K (1)ядерная война (1)ядерное оружие (1)claude sonnet 4 (1)zero trust (1)рутокен (1)Gemini 3.1 Flash (1)observability conf (1)Mercury 2 (1)Claude 4.5 Haiku (1)GPT-5.2 Mini (1)Inception (1)apple tv (1)формула-1 (1)трассы (1)путеводитель (1)суицид (1)Realtime API (1)gpt-realtime-1.5 (1)Аудиомодель (1)WebSocket (1)обновление моделей (1)видеомонтаж (1)multiplayer (1)ue (1)ProducerAI (1)Google Labs (1)виртуальный соавтор (1)MD Ryzen AI 400 (1)AM5 (1)APU (1)e2k (1)оплата труда (1)обучение нейронных сетей (1)гарри поттер (1)RAV4 (1)Digit (1)Agility (1)MEMORY.md (1)память сессий (1)авто-память (1)обновление Claude (1)ванадат (1)русы против ящеров 2 (1)Keenadu (1)китайский язык (1)консоль разработчика (1)RapidRAW 1.5.0 (1)CompressO 2.0.0 (1)Wireshark 4.6.4 (1)ONLYOFFICE DocumentServer 9.3.0 (1)osint (1)короб (1)дорси (1)square (1)tidal (1)Хабр для бизнеса (1)объявления (1)завышенные характеристики (1)Apache NetBeans 29 (1)Apache NetBeans (1)гель (1)желе (1)слизь (1)корпоративные пользователи (1)гибридные среды (1)облачные системы (1)яндекс банк (1)чехол (1)фреймворки (1)мышление (1)технопарк (1)дирижабли (1)консалтинг (1)повышение (1)портативный пк (1)legion go fold (1)студии (1)производство контента (1)sudo-rs (1)translate (1)тэц (1)Notion Custom Agents (1)агенты в notion (1)Custom Agents (1)торговля криптовалютами (1)роботрак (1)game ready (1)geforce (1)solar safeinspect (1)ракетные двигатели (1)ангара-1.2 (1)deckhouse stronghold (1)hashicorp vault (1)секреты (1)oppo (1)льдогенератор (1)copilot tasks (1)pplx-embed (1)двунаправленное внимание (1)ИИ-компании (1)обмен данными (1)финансовые организации (1)ИИ-системы в инженерии (1)рентабельность производства (1)Sophia Space (1)космические центры обработки данных (1)колонизация планет (1)refs (1)файловые системы (1)открытый стандарт MCP (1)ARR (1)судебные иски (1)burger king (1)вежливость (1)blue-ray (1)buffalo (1)приводы (1)Tails 7.5 (1)KataLib 5.2.1.0 (1)katalib (1)Дэн Симмонс (1)poco (1)кроссовки (1)резина (1)артемида-4 (1)лунные миссии (1)супермаркеты (1)блокировка рекламы (1)должности (1)нетехнические специальности (1)Dendy (1)kling 3.0 (1)veo 3.1 (1)инсайдерская торговля (1)yandex commerce protocol (1)яндекс пэй (1)яндекс сплит (1)яндекс kit (1)валерий стромов (1)роботы-уборщики (1)гкаванти (1)татарстан (1)claude opus 3 (1)substack (1)медиа киберлига (1)Прикладные нейросетевые технологии (1)gameдни (1)обсерватория имени веры рубин (1)ночное небо (1)астероиды (1)open claw (1)киностудии (1)learnlm (1)goal scheduled actions (1)Calibre 9.4 (1)apple app store (1)WinScript 2.0.0 (1)WinScript (1)аааа (1)визуальная новелла (1)tsukihime (1)дискеты (1)windows 365 link (1)корпоративные приложения (1)криптографические алгоритмы (1)https (1)деревья меркла (1)Fwupd 2.0.20 (1)claude remote control (1)one ui 8.5 (1)Shotcut 26.2 (1)гис антифрод (1)галактические скопления (1)протоскопление (1)grok voice agent api (1)киберклубы (1)раунд финансирования (1)grok 4.1 fast (1)glm 4.7 (1)rts-стратегии (1)соревнования llm (1)Yambda (1)аии (1)априори (1)graphcast (1)spank (1)робопротезы (1)Winslop 26.02.02 (1)MatX (1)онлайн-сервис (1)онлайн-сервисы (1)списания (1)красота (1)техноголоии (1)мбт (1)техника для дома (1)смарт-телевизор (1)statcounter (1)теги (1)волосы (1)алопеция (1)облысение (1)компакт-диски (1)названия (1)кириллица (1)вывески (1)реклама в сми (1)яндекс станция (1)голосовые интерфейсы (1)выборы (1)Яндекс Вебмастер (1)ИКС (1)Индекс качества сайта (1)print screen (1)клавиши (1)локальная разработка (1)localhost (1)подбор паролей (1)glocalme (1)unicord (1)silicon power (1)брак (1)Cloud Backup (1)smartapp (1)ремикс (1)вертикальные видео (1)minimax m2.5 (1)ryzen ai pro (1)zen 5 (1)конкурс студенченских работ (1)рельеф (1)горы (1)курорты (1)спам звонки борьба (1)stream (1)stream api (1)processor (1)processors (1)arm64 (1)6g (1)исследование программ (1)арпп отечественный софт (1)кризис DRAM (1)спрос (1)aeon (1)hexagon robotics (1)лейпциг (1)тест-кейсы (1)обеспечение качества (1)StaxRip 2.52.0 (1)StaxRip (1)iphone 17e (1)VPN-сервер (1)ipad air (1)m4 (1)Зеленые страницы (1)Красная книга разработчика (1)айфон (1)айфоны (1)айфономания (1)айфончики (1)айфонография (1)завышение цен (1)организация работы (1)организация времени (1)trek (1)пострадавшие (1)замена (1)Hyprland 0.54.0 (1)Armbian 26.2 (1)push-to-talk (1)транскрибация речи (1)Microslop (1)портативный аккумулятор (1)портативная батарея (1)воздушный транспорт (1)слух (1)глаза (1)nand flash (1)phison (1)предоплата (1)удаление приложения (1)налоговая служба (1)криптокошелек (1)финансовые пирамиды (1)платежная система (1)платежный шлюз (1)проценты (1)wink (1)okko (1)Верховный суд США (1)британская колумбия (1)часовые пояса (1)перевод часов (1)перевод времени (1)летнее время (1)ленточный интерфейс (1)ipad2 (1)ipad приложение (1)ipad маркетинг (1)samsung wallet (1)умный замок (1)автоматическая установка windows (1)ornl (1)министерство энергетики сша (1)институт (1)новые технологии (1)waterfall (1)vk security confab (1)4g (1)highlight reels (1)xbox ally x (1)хайлайт (1)перекупщики (1)OpenWrt 25.12 (1)OpenWrt (1)гигачат для бизнеса (1)сетчатка (1)наноДРАЙВ (1)тз (1)кабина обслуживания (1)AMA-сессия (1)опенспейсы (1)matrox (1)arc a380 (1)macbook air (1)жорж мельес (1)пьеро (1)фототехника (1)фотоаппаратура (1)фотоаппарат (1)фотоапарат (1)фотоаппарат для начинающих (1)фотоаппарат на android (1)фотоаппарат sony (1)Berkeley (1)ad-tech (1)adtech (1)MetaAI (1)доменное имя (1)Sedo (1)Bot.ai (1)GPT-5.3-Instant (1)gpt nano (1)экспорт данных (1)импорт данных (1)apple studio display (1)studio display (1)xdr (1)Pew Research Center (1)Fasten (1)Zed (1)Gram (1)MaxBlocker (1)Cozystack 1.0 (1)tpms (1)датчики давления (1)дешифровка (1)Цифровой Brand Day 2026 (1)безопасная разработка приложений (1)devsecops services (1)devsecops и devops (1)Anthropic Pentagon (1)Claude DeepSeek дистилляция (1)lm studio (1)баржи (1)море (1)зеленая энергетика (1)kingston fury (1)windows 12 (1)нейропроцессоры (1)downdetector (1)speedtest (1)ekahau (1)unity asset store (1)unity 6 (1)ассеты (1)arctic cooling (1)бот-атака (1)application layer (1)антибот (1)preventive proxy (1)багаж (1)windows 11 23h2 (1)интернет-подключение (1)сброс настроек (1)обновление windows (1)nana banana (1)corning gorilla glass (1)защитное стекло (1)стеклокерамика (1)прочность (1)motorola razr (1)новая версия (1)Музей криптографии (1)волна (1)вжух (1)uri (1)мвдиео (1)зима (1)шипы (1)аналог cursor (1)аналог claude code (1)аналог replit (1)аналог codex (1)аналог antigravity (1)аналог windsurf (1)альтернатива cusror (1)альтернатива cloude code (1)бесплатная ai ide (1)ai coding agent (1)учеба в it (1)coa (1)ключи активации (1)microsoft build (1)блокировки аккаунтов (1)squadron 42 (1)личные данные (1)socamm2 (1)сзи (1)плк (1)продуктовая геймификация (1)митапы для продактов (1)тестирование сайтов (1)dooh (1)макбук (1)макбуки программистам (1)макбуки (1)Whisper (1)SKILL.md (1)контекст (1)нейрости (1)dlc (1)Astrum Entertainment (1)Кровь на Хрустале (1)клетки (1)arduimo (1)app lab (1)Edge Impulse (1)машинное обучений (1)neural engine (1)NWinfo 1.6.1 (1)Nitrux 6.0.0 (1)тариф (1)защищенные смартфоны (1)ударопрочные гаджеты (1)web storm (1)php shtorm (1)goland (1)MPC-HC (1)беспроводная клавиатура (1)складные устройства (1)alice (1)раскладка (1)раскладка клавиатуры (1)торговля данными (1)tool search (1)новая модель (1)headphones a (1)AI glasses (1)конфиденциальность данных (1)EssilorLuxottica (1)abc-xyz (1)abc-сортировка (1)консалтинговые услуги (1)национальный мессенджер (1)Эльвира Набиуллина (1)сетка (1)it-подбор (1)тестирование на C# (1)кнопочные телефоны (1)Kairos (1)SpaceOne (1)оформление (1)whatsapp plus (1)вещание (1)русский мир (1)factset (1)cozystac (1)talos (1)обновление кс (1)кс 2 обновление (1)обновление кс2 (1)обновление cs (1)cs 2 обновление (1)последнее обновление кс2 (1)owasp top 10 (1)сторонние сервисы (1)агентства (1)samsung health (1)бизнес-решения (1)ит-бизнес (1)business development (1)суммаризация (1)y combinator (1)диктофон (1)звукозапись (1)pocket (1)kafkalet (1)Rust 1.94 (1)смартофны (1)samsung electronics (1)samsung apps store (1)samsung galaxy s ii (1)фармакомпании (1)экранное время (1)отказ от соцсетей (1)концентрация (1)геймер (1)Green-VLA (1)netlfix (1)interpositive (1)ccskrf (1)интернет-энциклопедия (1)united (1)авиаперевозки (1)microsoft bing (1)bing ai (1)установщик (1)ссылка (1)изображение (1)norton (1)телерадиовещание (1)технотекст 8 (1)diy или сделай сам (1)Amazon Connect Health (1)healthcare AI (1)HIPAA (1)AI в здравоохранении (1)медицинская автоматизация (1)Исследования и прогнозы (1)угроза (1)помощник (1)логирование (1)отладка (1)регистрация домена (1)автоматизации (1)akai (1)сэмплеры (1)музыкальные инструменты (1)сэмплирование (1)mpc sample (1)подразделение (1)сокращение расходов (1)soft skills (1)iss (1)Microsoft Research (1)Phi-4-Vision-Reasoning (1)мультимодальная модель (1)VL-задачи (1)BiDi (1)аудиомодели (1)ии диалог (1)млечный путь (1)местная группа галактик (1)конкурсы разработчиков (1)finebi (1)галерея дашбордов (1)tableau public (1)power bi community showcase (1)AGENTS.md (1)агентные workflow (1)Еврозона (1)Lightricks (1)LTX-2.3 (1)создание видео (1)портретное видео (1)замена батареи (1)Qwen-Max (1)bim просвет (1)оптимизация трудозатрат (1)финансовые модели (1)Guangdong (1)AI Plus (1)Shenzhen (1)minerva (1)archive (1)VadimLjovkin (1)avouner (1)aardvark (1)RustDesk 1.4.6 (1)картинка (1)WinForms (1)WinUI 3 (1)ios 16 (1)старые устройства (1)мобильные операторы (1)сохранение (1)перефразирование (1)document foundation (1)xlsx (1)material you (1)Codex Security (1)распознавание жестов (1)Postfix 3.11 (1)Postfix (1)редактор изображений (1)ieepa (1)Olmo Hybrid (1)Linux From Scratch 13.0 (1)гарда (1)бастион (1)икс холдинг (1)икс безопасность (1)steam frame (1)фонд Система (1)афк система (1)AI в медицине (1)FireSat (1)кванты (1)докинг (1)скрининг (1)суперкомпьютинг (1)иностранные инвестиции (1)метастазы (1)химиотерапия (1)API-ресурсы (1)Codex Open Source Fund (1)Firefox 22 (1)City Detect (1)Prudence Venture Capital (1)2024 YR4 (1)искусственный общий интеллект (1)Superhuman Adaptable Intelligence (1)sai (1)Unified Intelligence (1)унифицированный интеллект (1)визуальные данные (1)ROME (1)рабочая неделя (1)пятидневка (1)четырехдневка (1)PortableGL 0.100 (1)PortableGL (1)OpenGL (1)Wine 11.4 (1)Pizlix (1)Fil-C (1)playstation store (1)персональное предложение (1)ааа игры (1)ии-галлюцинации (1)iclr 2026 (1)triviaqa (1)hotpotqa (1)imdb (1)math (1)Caitlin Kalinowski (1)adult mode (1)Wrtn (1)chatgpt 5.4 xhigh (1)физика (1)ии-бенчмарки (1)британский музей (1)mac studio neo (1)Target Hospitality (1)AI-индустрия (1)luma ai (1)gpt image 1.5 (1)risebench (1)Pharma.AI (1)PPSSPP (1)PPSSPP 1.2 (1)Video Codec Converter (1)chardet (1)оборонные технологии (1)AI-этика (1)dual-use технологии (1)faq (1)digiKam 9.0.0 (1)open js (1)безопасность A (1)история видеоигр (1)цифровой архив (1)сознание ии-моделей (1)написание текстов (1)грамотность (1)эксперты (1)космическая еда (1)рацион (1)PETRUSHKA (1)instant checkout (1)бюджетные устройства (1)бюджетные смартфоны (1)Лайман-альфа (1)OpenMAX (1)copilot cowork (1)поиск человека (1)Путин (1)Promptfoo (1)карандаши (1)канцелярия (1)плодовая мушка (1)субсидирование тарифов (1)air (1)agentic development (1)developer tools (1)amd ryzen ai p100 (1)автоматическое ревью (1)Hewlett Packard Enterprise (1)AI-серверы (1)LibreCAD 2.2.1.4 (1)LibreCAD 2 (1)LibreCAD (1)Rust Coreutils 0.7.0 (1)HandBrake 1.11.0 (1)cs go (1)counter-strike go (1)cs (1)турниры (1)соревнования (1)battlefield (1)battlefield 6 (1)ea (1)criterion (1)dice (1)shazam (1)распознавание музыки (1)AirSnitch (1)RapidRAW 1.5.1 (1)митап в спб (1)backend митап (1)бэкенд митап (1)LLM-стек для PHP (1)AI в travel tech (1)солнечные панели (1)шлагбаумы (1)team yandex (1)mlbb (1)Mobile Legends Bang Bang (1)moba (1)мерцание (1)баги windows (1)код-ревью (1)запросы на изменения (1)тепловая карта (1)дашборд (1)bi-система (1)сообщество (1)arduino (1)arduino uno (1)одноплатный компьютер (1)qualcomm ai hub (1)периферийные вычисления (1)автономные системы (1)OBS Studio 32.1 (1)OBS Studio 32 (1)OBS Studio (1)курсы программирования (1)сокращение персонала (1)отмывание денег (1)k2cloud (1)standoff bug bounty (1)предустановка софта (1)предустановка по (1)XeniOS (1)решения для бизнеса (1)металлургия (1)аналитика бизнеса (1)металлургическая промышленность (1)VK HR Day 2026 (1)оргдизайн (1)касперский (1)AI-код (1)AI для программистов (1)AI-регулирование (1)безопасность AI (1)Ян Лекун (1)AMI Labs (1)Agents (1)Flow Studio (1)Wonder 3D (1)НСЛКС (1)использование ии (1)митапы (1)дринкапы (1)sre-инженер (1)devops-инженер (1)реклама в телеграме (1)самовосстанавливающийся материал (1)центр проектирования (1)рел софт (1)Лукоморье (1)Затея (1)пересылка (1)фотополимерная печать (1)экзоскелеты (1)кентавр (1)груз (1)AI-социальные сети (1)Meta Superintelligence Labs (1)валюта (1)DeaDBeeF 1.10.1 (1)DeaDBeeF (1)FreeBSD 14.4 (1)FreeBSD 14 (1)MiroFish (1)фондовый рынок (1)технологический сектор (1)мелкая бытовая техника (1)товары для дома (1)товары для кухни (1)лимфодиссекция (1)рак кишечника (1)лечение рака кишечника (1)операция рака кишечника (1)оперативное вмешательство (1)D1 (1)D2 (1)D3 (1)BIND 9 (1)comet (1)ии-браузеры (1)Windows 7 (1)Claude Code Review (1)autoresearch Karpathy (1)MacBook M5 Max (1)vibe training (1)биокомпьютер (1)suse (1)eqt (1)eqt ab (1)внедрение технологий (1)кремниева долина (1)gpl (1)consistency (1)zip (1)zip-бомбы (1)edr (1)обход защиты (1)Google AI (1)beelink (1)медицинский AI (1)AI-ассистенты в медицине (1)Охота за ошибками (1)марк руссинович (1)старый код (1)машинный код (1)outersloth (1)вклады (1)резолюция (1)поддержка пользователей (1)законодательство it (1)законодательство в иб (1)vk education (1)буткемп (1)кодовая база (1)поддержка кода (1)курс-переписка (1)SafeBoard (1)записи (1)интерактивные визуализации (1)режим обучения (1)static code analysis (1)prs (1)prs for music (1)лицензирование музыки (1)лев толстой (1)оцифровка документов (1)рукопись (1)vpn-клиент (1)обзоры (1)Стоматологический портал (1)запись в днк (1)Macrohard (1)Synopsys (1)Ansys (1)проектирование микросхем (1)chiplet (1)рутовый доступ (1)rooting (1)microsoft authenticator (1)HomeBank (1)HomeBank 5.10 (1)ffmpeg-over-ip (1)восток (1)марафон (1)8 марта (1)подарки (1)игровой контроллер (1)геймпад (1)трансформер (1)gemini embedding (1)объекты (1)слои (1)апгрейд (1)gpu-кластеры (1)gpu-сервер (1)процессоры amd (1)kademlia (1)пиринговые сети (1)хеш-таблицы (1)dht (1)прокси-сервисы (1)Mesh (1)швейцария (1)электронное голосование (1)usb-накопитель (1)пилотный проект (1)подсчёт голосов (1)personal computer (1)truenas (1)внутренняя разработка (1)сборка пакетов (1)сетевые хранилища (1)издательства (1)пиратст (1)интернет-библиотеки (1)expert review (1)пельмени (1)рынок найма (1)сломанный найм (1)фильтры (1)forethought (1)автомобильные системы (1)ремни безопасности (1)расход топлива (1)налоговые льготы для it-компаний (1)CromeOS (1)Black Market (1)роструд (1)Quicksort (1)логика Хоара (1)ошибка на миллиард долларов (1)премия Тьюринга (1)ALGOL (1)редактор (1)antiddos (1)ии в разработке (1)кадровый рост (1)требования к разработке (1)командообразование (1)developer relations (1)девкиты (1)делимобиль (1)каршеринг (1)MIK32 (1)амур (1)импорт настроек (1)плагины IDE (1)настройка IDE (1)обновление OpenIDE (1)карьерный рост (1)столица (1)parseword (1)криптографические кроссворды (1)карта страховых компаний (1)киберстрахование (1)тренды рынка (1)рекордер (1)blu-ray (1)mtia (1)servicedesk (1)доход (1)Авито Реклама (1)Смартфон за внимание (1)управление it-инфраструктурой (1)ipam (1)smart brick (1)умный кубик (1)p2s (1)фильтр (1)биометрия (1)пин-код (1)отпечаток пальца (1)поиск устройств (1)Kitty 0.46 (1)Sigil 2.7.5 (1)PeerTube 8.1 (1)avocado (1)Professional AI Bully (1)ТехноГТО (1)curl 8.19 (1)curl 8 (1)id (1)tee (1)pgo (1)профилирование приложений (1)дейтинг-приложения (1)быстрые свидания (1)нарайен (1)телепрограмма (1)pokemon go (1)геопространственная аналитика (1)модель мира (1)картографирование (1)либ (1)команда (1)таксофоны (1)rabbit (1)нетбуки (1)ультрабуки (1)cyberdeck (1)hpe aruba (1)коммутаторы (1)alphaevolve (1)демо-день (1)АМОР (1)монтажник (1)разработчик (1)лайфхак (1)мозговой интерфейс (1)конвейер (1)автопарки (1)телематика (1)автомобильные данные (1)core ultra 200s (1)core ultra (1)core ultra 200s plus (1)arrow lake (1)mini app (1)mini apps (1)модерация приложений (1)Разработка мини аппов (1)Модерация мини аппов (1)лондон (1)господдержка (1)cs 1.6 (1)gocloud (1)cloud.ru (1)ds инженеры (1)управление запасами (1)OpenJarvis (1)офлайн карты (1)бумажные карты (1)blackwell b200 (1)контекстное окно 1 миллион токенов (1)длинный контекст LLM (1)API claude pricing (1)SPARCS (1)Fwupd 2.1.1 (1)Calibre 9.5 (1)PayQR (1)vtol (1)evtol (1)число пи (1)backblaze (1)открытые данные (1)сенат (1)Chrome 146 (1)telegram-каналы (1)Nissan (1)автопроизводители (1)японский рынок (1)DeerFlow (1)LangGraph (1)Суб-агенты (1)CAICT (1)Steven Spielberg (1)AI в кино (1)технологии в киноиндустрии (1)SXSW 2026 (1)URBAN MOBILITY OBJECT (1)Copilot 300 (1)Microsoft Elevate (1)африка (1)голова (1)ЭФКО (1)создание по (1)солар секьюрити (1)группа компаний солар (1)финансовые показатели (1)Ask Maps (1)Street View (1)новость (1)ситуация (1)сегодня выходной (1)CPU-Z 2.19 (1)Glow 26.5 (1)сетевой сбой (1)MouseControl (1)режиссура (1)ии в кино (1)South by Southwest (1)Anthropic акция (1)удвоение лимитов (1)непиковые часы (1)v-color (1)manta (1)соединение (1)Nyne (1)AI-технологии (1)человеческий контекст (1)голосовой помощник (1)ответы (1)музыкальные предпочтения (1)Taste Profile (1)Discover Weekly (1)Wrapped (1)buzzfeed (1)Hume AI (1)TADA (1)речь (1)super nintendo (1)snes (1)super fx (1)рекламные интеграции (1)alphafold (1)Peacock (1)NBCUniversal (1)мобильные развлечения (1)McKinsey (1)AI2 (1)роботизированные системы (1)виртуальные среды (1)маневренность (1)AI-DJ (1)алгоритмы рекомендаций (1)atariology (1)музыка и AI (1)инфраструктура AI (1)рынок труда в технологиях (1)подборки (1)война (1)солнечная энергетика (1)ветряная энергия (1)сэс (1)Edge 146 (1)GIMP 3.2 (1)GIMP 3 (1)GIMP (1)сетевая недоступность (1)Linux 6.12 (1)Debian 13.4 (1)debian squeeze (1)ReVanced 2.0 (1)ReVanced (1)charter communications (1)кабельный интернет (1)nano360 (1)облачные данные (1)управление документацией (1)проектная документация (1)google play store (1)apple music (1)метатеги (1)windows deployment services (1)protondb (1)steamos (1)rollme (1)vast (1)samsung galaxy connect (1)Claude Certified Architect (1)сертификация Anthropic (1)экзамен Claude (1)Model Context Protocol (1)activtrak (1)продуктивность работы (1)многозадачность (1)рабочие задачи (1)java virtual machine (1)quarkus (1)java time (1)целостность (1)воспроизводимость (1)цепочка поставок (1)cgi group (1)взломы (1)онлайн-бронирование (1)тревел (1)fallout 4 (1)гибрид (1)cowork (1)Accel (1)AI wrappers (1)акселераторы стартапов (1)инвестиции в AI (1)технологические стартапы (1)почтовая связь (1)дискуссия (1)цифровая экономика (1)аппаратный хакинг (1)ai devtools (1)usb (1)usb-флэшки (1)флешки (1)холодное хранение данных (1)автоматизация процессов (1)цифровизация строительства (1)строительные технологии (1)исполнительная документация (1)enterprise-ПО (1)бред (1)бредовые идеи (1)аркадий волож (1)save myrient (1)parallels (1)Percepta (1)серверная оптимизация (1)openclaw-rl (1)пристонский университет (1)майнеры (1)револют (1)airpods max (1)дорожная карта (1)manus my computer (1)Сохранить как (1)молния (1)prompt engineering (1)memory management (1)trifold (1)трикладушка (1)складной смартфон (1)encyclopedia britannica (1)судебное разбирательство (1)chatgpt 4.5 (1)DRIVE Hyperion (1)Feynman (1)groq (1)SuperTux 0.7 (1)SuperTux (1)NoCopilotKey (1)Ctrl (1)зарплатный сговор (1)nemclaw (1)автоматизация анализа (1)bitflip (1)ИИ-клиника (1)среда выполнения (1)локальные вычислительные сети (1)nix (1)nixos (1)linux kernel development (1)britannica (1)британская энциклопедия (1)Falcon 9 (1)космическая связь (1)Роберт Годдард (1)освоение космоса (1)космические запуски (1)технологии связи (1)gr00t (1)взрослые (1)секс (1)apt-группировки (1)снг (1)картинки (1)рнк (1)рюгу (1)creative (1)sound blaster (1)объемный звук (1)motionvfx (1)final cut (1)final cut pro (1)шаблоны (1)доступ к ии-моделям (1)windows learning center (1)фотореализм (1)цифровая инфраструктура (1)условия использования (1)быстрая зарядка (1)воздушное охлаждение (1)папки (1)выбор имени (1)производственная система росатома (1)Онлайн-продажи (1)онлайн-оборот (1)dust (1)Picsart (1)автоматизация контента (1)SMM (1)leanstral (1)lean (1)ноуты (1)цвета (1)Nvidia H200 NVL (1)Mistral Small 4 (1)Mixture of Experts (1)reasoning effort (1)Apache 2.0 (1)openjdk (1)g1 (1)jdk 26 (1)jep (1)jeps (1)gamma (1)мачты (1)стандарты связи (1)башенные компании (1)сорняки (1)ботаника (1)AI для кода (1)it-ипотека (1)резиденты (1)налоговое законодательство (1)chatgpt 5.4 mini (1)chatgpt 5.4 nano (1)манипулирование людьми (1)кри (1)конференция разработчиков игр (1)игропром (1)специальности (1)археология (1)пение китов (1)пластинки (1)аудиозапись (1)PhysiOpt (1)3d-модели (1)экспортные ограничения (1)Hopper (1)авто (1)электрокары (1)электроскутер (1)стабилизация (1)FFmpeg 8.1 (1)Мобильный криминалист (1)Marknote 1.5 (1)Marknote (1)Newton (1)физическое моделирование (1)симуляция реальности (1)Blender 5.1 (1)midjourney (1)midjourney v8 (1)dispatch (1)Берлога (1)Nemotron 3 Super (1)DGX Station (1)Okara AI CMO (1)химическое оружие (1)взрывчатка (1)взрывчатые вещества (1)грязная бомба (1)copilot chat (1)корпоративная лицензия (1)доклад (1)спутниковая группировка (1)pt esc (1)высокое качество (1)режим (1)galaxy 26 ultra (1)диспеи (1)ps portal (1)playstation portal (1)1080p (1)system76 (1)amd ryzen 9 9950x3d (1)rx 9070 xt (1)solar webproxy (1)машинный перевод (1)patreon (1)спонсорство (1)скандалы (1)инфомационная безопасность (1)инфраструктура it-компании (1)отказоустойчивые системы (1)pwa (1)electron (1)seedance (1)большие данные (1)бизнес-класс (1)boeing 737 (1)airbus a330 (1)голос в текст (1)автоматизация текста (1)flo (1)облако mail.ru (1)кастомные модели (1)корпоративные решения (1)jellyfish (1)качество кода (1)iphone 71e (1)вхдящий перевод (1)PGConf.Россия (1)pgconf.russia 2026 (1)PGConf.Russia (1)восход-2 (1)росархив (1)рекурсивное обучение (1)жим кода (1)тусур (1)Rudius (1)свойства материалов (1)будущее ИИ (1)BMG (1)fair use (1)systemd 260 (1)systemd (1)BillyPro (1)Яндекс Интернетометр (1)Интернетометр (1)Test core (1)Debug (1)антимитап (1)Hard Skills (1)офлайн мероприятие (1)HopToDesk 1.45.10 (1)hoptodesk (1)покупатели (1)покупка данных (1)наблюдение (1)рег.облако (1)рбк (1)рбк-центр (1)запуск проекта (1)запуск продукта (1)запуск приложений (1)запуск проектов (1)запуск продуктов на рынок (1)работа за границей (1)работа за рубежом (1)безлимитный интернет (1)ai overview (1)падение трафика (1)боковая панель (1)CD40 (1)кембридж (1)биткойн (1)обрыв (1)устойчивость (1)голосовые роботы (1)колл-боты (1)нацспектр (1)гуманоиды (1)роботостроение (1)инфлюенсеры (1)хранилище данных (1)xbox series (1)quick resume (1)hsbc (1)кузнечик (1)airtunes (1)метавселенные (1)horizon worlds (1)quest (1)Vibecode (1)ninkear (1)подделка (1)обман покупателей (1)ardor gaming (1)iru (1)pdf-редактор (1)ред экспо (1)low-code платформа (1)государство и интернет (1)сапр системы (1)Meshtastic (1)Qwen3.5-Max (1)Astral (1)dev tools (1)безопастность (1)Liquid Glass (1)NoClaw (1)Samba 4.24.0 (1)Samba 4.24 (1)Samba 4 (1)сид-фраза (1)аппаратные криптокошельки (1)хищение (1)casio (1)s100x (1)лак (1)лаковое дерево (1)проблемы со связью (1)ИИ-инженер (1)codex ai (1)atlas (1)супераппы (1)сервис доставки (1)задания (1)доплата (1)обучение роботов (1)мозг-компьютер (1)нейроинтерфейсы (1)система управления (1)атомные часы (1)точное время (1)cpt (1)квантовый эффект (1)рубидий (1)perplexity health (1)ремешки (1)ремешки для часов (1)кожа (1)AI чат (1)confer (1)мокси марлинспайк (1)rivr (1)rivr one (1)anymal (1)роботы-доставщики (1)россети (1)провайдеры интернет (1)дом (1)туризм (1)ml-engineer (1)инженер машинного обучения (1)Counter-Strike 1.6 (1)Рекламная сеть Яндекса (1)физические лица (1)индивидуальные предприниматели (1)самозанятость (1)медийная реклама (1)VK Инклюзия 2026 (1)цифровая доступность (1)нарушение (1)модель (1)hbm4 (1)системы резервного копирования (1)super micro computer (1)MAI-Image-2 (1)корнеллский университет (1)медиа кибер лига (1)походка (1)судебная система (1)Wink Книги (1)кишечник (1)микробиом (1)opera gx (1)darkweb (1)весенняя распродажа стим (1)весенняя распродажа стим 2026. (1)весенняя распродажа стим игры (1)распродажа steam (1)распродажа стим (1)Wayland 1.25 (1)Wayland (1)KiCad 10.0 (1)wordpress.com (1)контент сайта (1)дизайн сайта (1)автоматические обновления (1)China tech (1)алкотестеры (1)Radicle 1.7 (1)Radicle (1)подмена заголовков (1)НЭТИ (1)Тихий угол (1)adobe firefly (1)custom (1)дообучение модели (1)cbs news radio (1)мэа (1)агентство (1)энергетический кризис (1)экономия энергии (1)быт (1)авианосец (1)пробежка (1)update (1)доверие (1)Wine 11.5 (1)OpenShot 3.5.0 (1)openshot (1)настольгия (1)конвертация ресурсов (1)Бункер 3D (1)Лаборатория 3D (1)Крепость 3D (1)gzdoom (1)крокус экспо (1)crypto.com (1)hub (1)Cambalache 1.0 (1)Cambalache (1)инди-разработчики (1)продвижение игр (1)монетизация игр (1)учётная запись microsoft (1)ELKS 0.9 (1)индийский океан (1)социальная сеть (1)новостные статьи (1)заголовки статей (1)Google Discover (1)ElevenCreative (1)Nemotron-Cascade 2 (1)открытая языковая модель (1)математическая олимпиада (1)Sigil 2.7.6 (1)авария на байконуре (1)ангара (1)пилотируемая космическая программа (1)iposharks (1)олимпиада по ии (1)мировые рекорды (1)спринт (1)робот-гуманоид (1)скорость бега (1)ИИ-генераторы изображений (1)Firefly Custom Models (1)художественные стили (1)дизайны персонажей (1)RapidRAW 1.5.2 (1)декстоп (1)РАо (1)музеи (1)DoctorClaw (1)суперземли (1)стипендия (1)стипендиальная программа (1)математические задачи (1)Квантум Парк (1)фотонные интегральные схемы (1)Ghostling (1)libghostty (1)CopySpeak (1)WHO (1)новости недели (1)quick share (1)обмен файлами (1)контекстная реклама (1)бесплатный тариф (1)рост (1)Immich 2.6 (1)Immich (1)агрессия (1)пассажиры (1)ттк (1)аптеки (1)lux (1)lux optics (1)halide (1)выживание (1)Home Cinema 2.6.4 (1)YandexGPT (1)олег кононенко (1)Яндекс Маршрутизация (1)выброс (1)ingress nginx (1)gateway api (1)управление трафиком (1)проверка данных (1)биометрическая аутентификация (1)halter (1)ошейники (1)умные ошейники (1)смарт-устройства (1)коровы (1)скот (1)trivy (1)червь (1)автоматизированная система (1)призы (1)starlette (1)restapi (1)asgi (1)фреймфорк (1)запрещенный контент (1)Balmuda (1)the clock (1)будильник (1)vkjt (1)исследователь (1)локальные llm (1)федор конюхов (1)rtx 4060 (1)росинкас (1)Product Engineer (1)внедрение ии в разработку (1)Team Topologies (1)Product Focus Club (1)Ageless Linux (1)mitm-атаки (1)технический разбор (1)Raspberry Pi Connect (1)ota (1)газпром-медиа (1)газпром-медиа холдинг (1)александр жаров (1)телеканалы (1)premiere (1)партнерство компаний (1)Helion (1)термоядерная энергетика (1)энергетическая выработка (1)java26 (1)jdk26 (1)DLSS 5 Anything (1)ИИ-бьютификатор (1)MiMo-V2-Omni (1)трение (1)магнетизм (1)закон Амонтона (1)плата-ускоритель (1)нот (1)отрасль сбора урожая (1)премия за разработку (1)двойные звёзды (1)grep (1)текстовый поиск (1).gitignore (1)контроль (1)Firefox 149.0 (1)Bottles 63.0 (1)Bottles (1)сессия (1)simbirsoft (1)джун (1)триграммы (1)n-grams (1)DHS (1)Америка (1)game optimizing service (1)gos (1)замедление (1)galaxy s22 (1)s22 (1)яндекс доставка (1)яндекс еда (1)программная инженерия (1)накрутка (1)роялти (1)авторские отчисления (1)мультимедиа (1)multimodality (1)eff (1)защита контента (1)архивация (1)собственная разработка (1)time-to-market (1)бэклог (1)вузы России (1)AI pilot (1)markswebb (1)интернет-банкинг (1)топ (1)соревнования разработчиков (1)заказ такси (1)монополизация (1)Эфир-600 (1)МНИИРС (1)привлечение клиентов (1)сегвей (1)segway (1)amd ryzen 5 (1)подмена (1)яндекс ровер (1)aisuru (1)jackskid (1)mossad (1)стилизация (1)mail (1)astra linux server (1)харденинг (1)бэкап (1)rubackup (1)киберпротект (1)береста рк (1)tongyi lab (1)funaudiollm (1)alibaba group (1)prismaudio (1)рекламные технологии (1)депрессия (1)яндекс дропс (1)красивые номера (1)автомобильные номера (1)цена лицензии (1)echo show (1)модерация сообществ (1)аккредитация (1)среднее профессиональное (1)gigachat 3.1 ultra (1)gigachat 3.1 lightning (1)замедление youtube (1)directx (1)gpt-oss-safeguard (1)разработка ИИ-приложений (1)mova (1)AtomForm Palette 300 (1)Palette 300 (1)патенты на программное обеспечение (1)изобретения (1)ноу-хау (1)правообладатели (1)поддержка проекта (1)московский инновационный кластер (1)AnyDesk 9.6.12 (1)cliamp (1)OpenAI Astral (1)Claude Computer Use (1)Unsloth Studio (1)Instant Grep (1)Kimi K2.7 (1)регистрация товарного знака (1)звуковой дизайн (1)Qt 6.11 (1)Qt 6 (1)ногти (1)стилус (1)пальцы (1)луизиана (1)исполнители (1)профили (1)TypeScript 6.0 (1)мах (1)nvme (1)ускорение (1)красные гиганты (1)артемида-5 (1)иностранные товары (1)Совфед (1)академическая этика (1)AI literacy (1)campo (1)auto mode (1)ИИ для разработчиков (1)sandbox (1)viper (1)аттестация гис (1)аттестация фстэк (1)dark outlaw (1)dark outlaw games (1)закрытие студии (1)биологический возраст (1)mcp-server (1)mcp-servers (1)объекты кии (1)кибербезопасность асу тп (1)иб асу (1)оценка зрелости (1)киберфизические системы (1)риски цепочки поставок (1)fauna (1)fauna robotics (1)ray-ban display (1)запасы (1)kali linux (1)kali linux 2025.4 (1)этичный хакинг (1)Krita 6.0 (1)Krita 5.3 (1)тестирование веб-приложений (1)iac (1)инфраструктура как код (1)gitops (1)gitops-практики (1)конфигурации (1)установка мобильных приложений (1)конструктивная кибербезопасность (1)обучения (1)машинное обученией (1)кампус (1)демоатлас (1)примеры (1)self service bi (1)ядерные двигатели (1)startup (1)ларри эллисон (1)сергей брин (1)2g (1)elevenlabs eleven (1)inworld tts (1)minimax speech (1)google wavenet (1)kokoro (1)microsoft azure neural (1)accuweather (1)прогнозы погоды (1)lyria 3 pro (1)фссп (1)взыскание (1)pine64 (1)PineTime (1)PineTime Pro (1)ИИ в медицине (1)radiology (1)Gemini 2.5 Pro (1)Llama 4 Maverick (1)закон об ИИ (1)AI Act (1)state AI laws (1)arm agi (1)треки (1)создание (1)приватность данных (1)Mozilla Thunderbird 149 (1)VitruvianOS (1)минобороны (1)военкомат (1)5 дней (1)FreeCAD 1.1 (1)FreeCAD (1)newegg (1)баг-репорты (1)TurboQuant (1)cox (1)cox communication (1)Квантование (1)Рынок акций (1)wifi (1)Umo 3 (1)sonova (1)слуховые аппараты (1)потребительская электроника (1)captcha (1)проверка (1)размеры (1)компактность (1)бумбокс (1)аудиофилы (1)sharp (1)кассеты (1)aux (1)магнитофоны (1)dos-атака (1)иммиграция (1)еком (1)еком и вино (1)ecom (1)ecommerce (1)векторное квантование (1)безопасность сайтов (1)bi.zone (1)bi.zone bugbounty (1)Польша (1)ядерная инфраструктура (1)MARIA (1)yahoo (1)Connekt (1)HTTP-клиент (1)DBeaver (1)REST (1)гардаdbf (1)защита баз данных (1)AGI CPU (1)Rebellions (1)K-Nvidia (1)чипы для ИИ (1)generative models (1)заемщики (1)цифровой профиль (1)reality labs (1)магистральные сети (1)денежные переводы (1)национальная платёжная система (1)легализация (1)регулирование криптовалют в россии (1)обмен знаниями (1)информация (1)ии в кибербезопасности (1)rotocall (1)электронные часы (1)цифровые часы (1)головной мозг (1)неокортекс (1)атлас мозга (1)эволюция человека (1)аутизм (1)промышленная разработка (1)3data (1)Биржа ЦТС (1)мощности в аренду (1)ии-бот (1)глиф (1)afeela (1)sony honda mobility (1)shm (1)ебс (1)изменения (1)Stackland (1)технический менеджмент (1)решение кейсов (1)soft skills руководителя (1)менеджмент проектов (1)нестандартные решения (1)переменный ток (1)Мир дронов (1)миран (1)менеджмент в it (1)Gemini 3.1 Flash Live (1)usps (1)двигатель (1)минфин россии (1)Fplus (1)литограф (1)вдеокарты (1)inno3d (1)geforce rtx 4090 (1)Apple Business (1)антиматерия (1)ангелы и демоны (1)машинное творчество (1)Voxtral TTS (1)voice ai (1)Samsung Browser (1)TRIBE (1)TRIBE v2 (1)CopyQ 14.0 (1)Doom Over DNS (1)Tails 7.6 (1)dji avata (1)dji avata 360 (1)fpv (1)360 (1)DietPi 10.2 (1)sata ssd (1)samsung evo (1)tlc nand (1)dns-туннелирование (1)драйверы ядра (1)подпись (1)корневой сертификат windows (1)whcp (1)проектирование ИЖС (1)автоматизация проектирования (1)малоэтажное строительство (1)моя волна (1)сокрытие данных (1)анонимность (1)mac pro (1)редактирование сообщений (1)half-life 2 (1)моды для игр (1)mods (1)kerbal space program (1)ретро-компьютеры (1)Lunnen Work (1)Премия Абеля (1)supersonic (1)ironsource (1)продажа компании (1)комбинаторные объявления (1)смарт-телевизоры (1)vizio os (1)квебек (1)регулятор (1)бука (1)plantuml (1)цифровое издание (1)basis sdn (1)brax (1)open_slate (1)грамота.ру (1)термины в ит (1)термины в айти (1)хукэда (1)дозаправка (1)заправка на орбите (1)спутник-заправщик (1)научные публикации (1)open research europe (1)кьюриосити (1)curiosity (1)марсоходы (1)роверы (1)колеса (1)космология (1)постоянная хаббла (1)ml-dsa (1)android keystore (1)ZDI-CAN-30207 (1)gitverse (1)импорт товаров (1)еаэс (1)грузовые перевозки (1)акцизы (1)поведение ИИ (1)alignment (1)ai assistants (1)CUDA (1)950PR (1)RAMmageddon (1)память для ИИ (1)IPO в США (1)LibreQoS 2.0 (1)LibreQoS (1)languagetool (1)проверка грамматики (1)орфография (1)расширение для браузера (1)электрики (1)рабочие профессии (1)кредит (1)кредит на год (1)Calibre 9.6 (1)финге (1)cfexpress (1)ToolBench (1)правительство сша (1)ganance (1)heir (1)дизайнеры (1)hevc (1)dolby (1)data poisoning (1)защита ИИ (1)ценообразование игр (1)Ави Pro (1)AI в политике (1)политическая реклама (1)misinformation (1)regulation (1)election tech (1)плазма (1)термоядерный синтез (1)gemini pro (1)microsoft access (1)SwiftUI (1)cssDoom (1)css (1)операция триангуляция (1)ipados (1)Monogram (1)yandex ml prize (1)электромоторы (1)выход из строя (1)егэ по информатике (1)кубок яндекс образования (1)яндекс образование (1)старшеклассники (1)coca-cola (1)средство индивидуальной мобильности (1)сборка (1)Nmap 7.99 (1)Nmap (1)шахматы (1)Swift 6.3 (1)Swift 6 (1)фишинговые ссылки (1)фишинговый сайт (1)магистартура (1)искусственный интеллек (1)онлайн-обучение (1)нативный софт (1)Froggy-BLC (1)почтовые клиенты (1)VibeGen (1)спч (1)низкая околоземная орбита (1)катоды (1)топливо из воздуха (1)опыт работы (1)личная жизнь (1)defender (1)handala (1)среднее специальное образование (1)kpi (1)AT Protocol (1)atproto (1)кастомные ленты (1)децентрализованные соцсети (1)австрия (1)компиляторы (1)поиск питомцев (1)MicroPythonOS 0.9.0 (1)MicroPythonOS (1)tp-link (1)archer nx (1)кварцевые часы (1)аналоговые часы (1)доменные споры (1)loreal (1)A-Evolve (1)эскалаторы (1)telnyx (1)wav (1)SystemRescue 13.0. (1)systemrescue (1)Winslopr (1)Windows Slop Remover (1)технический писатель (1)гост 34 (1)sphynx (1)docs-as-code (1)Mixxx 2.5.6 (1)Mixxx (1)персонализация контента (1)электронный ридер (1)читалка (1)газета (1)rss (1)instapaper (1)wallabag (1)клиентская поддержка (1)база знаний (1)Omnibot (1)ProЗнания (1)самозапрет (1)поиск windows (1)долговое финансирование (1)epilogue (1)gb operator (1)retrace (1)game boy (1)gba (1)gbc (1)lockdown mode (1)режим блокировки (1)чемпионат (1)neoverse (1)neoverse v3 (1)esp32 (1)дроны квадрокоптер (1)детектор (1)macos x (1)os x (1)КРОК (1)GPU as a Service (1)джетлаг (1)ночь (1)лоукостер (1)nand (1)керамические составы (1)платные приложения (1)ai-гонка (1)работа с поставщиками (1)подрядчик (1)транспортный налог (1)износ (1)ютуберы (1)стриминги (1)инфраструктура цод (1)виртуализация серверов (1)виртуализация данных (1)on-prem vs облако (1)свободное по (1)уголовная ответственность (1)ubuntu mate (1)галактика (1)carplay (1)т-авто (1)классифайд (1)симуляторы гонок (1)дальнобойщики (1)Eli Lilly (1)клинические испытания (1)операторы мобильной связи (1)т2 мобайл (1)claw (1)harmonyos (1)apple distribution international (1)кинопрокат (1)фильм (1)data governance (1)data quality (1)cyberone (1)бионические потовые железы (1)бионическая рука (1)ланит (1)айтеко (1)hwo (1)внеземная жизнь (1)агенты по программированию (1)Гонец (1)спутниковая система (1)capcut (1)Video Studio (1)генератор полного цикла (1)видеоролики (1)рекламные ролики (1)raycast (1)антимонопольное законодательство (1)топ-ит (1)белый списов (1)госты (1)биопечать (1)задержания (1)рфрит (1)Suno v 5.5 (1)qwen3.5-omni (1)X300 Ultra (1)камерофон (1)мобильная фотография (1)GitRiver (1)GitRiver 1.0 (1)vpn-сервис (1)vgate (1)eidos montreal (1)embracer (1)embracer group (1)deus ex (1)fable (1)adobe illustrator (1)векторная графика (1)вращение (1)графический дизайн (1)instagram plus (1)Anthropic Capybara утечка (1)Claude Code лимиты (1)Figma MCP (1)Stripe Projects.dev (1)Sora закрытие (1)intel arc (1)telegram premium (1)продление подписки (1)обратный отсчет (1)sls (1)олимпиада по информатике (1)финал (1)business (1)нагревание (1)нагрев (1)тепло (1)google play console (1)android developer console (1)проверка приложений (1)PicView 4.2.0 (1)PicView (1)электронная документация (1)ксо (1)ios 26.4 (1)python3 (1)python 3 (1)boston consulting group (1)интеллектуальный труд (1)истощение (1)canary (1)сборки (1)command line (1)оптимизация производительности (1)рабочие нагрузки (1)Multi-AZ (1)катастрофоустойчивость (1)облачные базы данных (1)DR (1)RTO (1)RPO (1)Eltex (1)400G (1)MES5700-32 (1)Spine-Leaf (1)EVPN (1)VXLAN (1)ip-телефония (1)ScaleOps (1)оптимизация затрат (1)Series C (1)Insight Partners (1)voip (1)датацентр (1)налог (1)налоговый кодекс (1)канал (1)утечка исходного кода (1)source map (1)feature flags (1)нереализованные функции (1)tap to share (1)передача файлов (1)rec room (1)видеонаблюдение через интернет (1)видеонаблюдение как сервис (1)smart home (1)внедрение ии в компаниях (1)экономический эффект ии (1)госзнаки (1)урбанизм (1)ocx (1)министерство обороны (1)пулл-реквест (1)инсталляторы (1)archinstall (1)starfield (1)bethesda (1)Zhipu (1)тектсолит (1)Starcloud 3 (1)трансфер (1)Колледжи (1)РСХБ.Цифра (1)windows app (1)промышленные роботы (1)производственная линия (1)ртк (1)шпд (1)AutoClaw (1)агент OpenClaw (1)quantum (1)тг (1)размещение акций (1)рынок инвестиций (1)Harrier-OSS-v1 (1)многоязычные модели (1)встраивание текста (1)семантические представления (1)MTEB v2 (1)Google Quantum AI (1)гостевые аккаунты (1)гидропоника (1)видеогенератор (1)ии-генератор видео (1)всемирный день бэкапа (1)день резервного копирования (1)праздник (1)opera neon (1)НСФР (1)залог (1)московский кредитный банк (1)госкорпорация (1)экспорт (1)технологический суверенитет (1)finder (1)Little Finder Guy (1)маскот (1)персонаж (1)limx (1)адрес (1)alt mobile (1)ALT Mobile 11.0 (1)реестр минцифры (1)mfg (1)toshiba (1)smr (1)черепичная магнитная запись (1)гипермасштабируемые цоды (1)емкость hdd (1)аномалия (1)leolabs (1)потеря связи (1)словарь (1)иностранные слова (1)голограммы (1)виртуальный помощник (1)ии-компаньоны (1)аватар (1)шутки программистов (1)созвоны (1)ретро (1)развлечения (1)уроки НТО (1)кружковое движение (1)железо и электроника (1)редактирование текстов (1)сканы (1)ии-кластеры (1)veo 3.1 lite (1)офисные приложения (1)proton workspace (1)baidu apollo (1)беспилотные такси (1)4MLinux 51.0 (1)4MLinux (1)Neovim 0.12 (1)neovim (1)восстановленные (1)Sherpa Robotics (1)Sherpa Autopilot (1)железнодорожный транспорт (1)железнодорожная сеть (1)электронная подпись (1)IDC (1)Slackbot (1)Agentforce (1)КНДР (1)UNC1069 (1)уроки (1)онлайн-курс (1)уголовное наказание (1)картинг (1)сверхпроводимость (1)claw code (1)сигрид чжин (1)внутриком (1)центр хруничева (1)цифровая грамотность (1)tinycorp (1)внешние видеокарты (1)egpu (1)Rspamd 4.0.0 (1)незрячие и слабовидящие (1)репетитор ai (1)яндекс учебник (1)Александр Ведяхин (1)тренды финтеха (1)OPC (1)частоты (1)wan (1)wan2.7-image (1)raspberry pi 4 (1)open banking (1)банковские API (1)николас карлини (1)orm (1)hibernate (1)hibernate orm (1)hibernate proxy (1)hibernate cache (1)НИИМЭ (1)интегральные микросхемы (1)лазерный микроскоп (1)лечение рака (1)атом (1)кама (1)matrix-game 3.0 (1)skywork ai (1)интерактивное видео (1)северо-западный университет (1)модульные роботы (1)диагностика (1)sara (1)telemt (1)GnuCash 5.15 (1)gnucash (1)PDFsam 6.0.0 (1)pdf split and merge (1)pdfsam (1)мвд рф (1)гибридный поиск (1)knn-search (1)full text search (1)полнотекстовый поиск (1)database optimization (1)release (1)автоматизация аудита (1)соответствие требованиям (1)внутренний контроль (1)ситимобил (1)таксовичкоф (1)грузовичков (1)городские сервисы (1)веб-сервисы (1)балансировщик нагрузки (1)обонятельный дисплей (1)ароматы (1)ароматизатор (1)Qwen3.6-plus (1)sbom (1)codescoring (1)система управления контентом (1)бессерверная архитектура (1)веб-разработа (1)Пулково (1)роевой ИИ (1)беспилотные тягачи (1)аэропорт (1)cognitive pilot (1)бикальчук (1)розница мвидео (1)больницы (1)радиология (1)рентгенология (1)IT-рынок (1)кадры (1)АКАР (1)рынок рекламы (1)intune (1)исследовать (1)perplexity ai (1)idm (1)4d (1)лабиринты (1)демоверсии (1)Cognichip (1)chip design (1)Lip-Bu Tan (1)абд (1)bigme (1)hibreak (1)hibreak plus (1)День Поиска (1)ps 5 (1)ps 5 pro (1)чехлы (1)изогнутая панель (1)exchange (1)решение проблемы (1)prometheus (1)ит-оборудование (1)налоговые резиденты (1)heroes might and magic (1)heroes (1)olden era (1)unfrozen (1)пошаговые стратегии (1)youtube tv (1)российское ритейл шоу (1)retail tech (1)генеративный интеллект (1)Terminal-Bench (1)Chery (1)Land Rover (1)Freelander (1)runit (1)vbywbahs (1)django (1)sql-инъекция (1)уявзимости (1)geodjango (1)vulnerability management (1)сара фрайар (1)грег брокман (1)p2p платежи (1)рассрочка (1)bnpl (1)x402 (1)ios 18 (1)Gemini 3 (1)ThroughLine (1)чатбот (1)кризисная поддержка (1)экстремизм (1)iclod (1)проверка работ (1)mai-voice-1 (1)mai-transcribe-1 (1)расшифровка речи (1)cursor 3 (1)Unigine 2.21 (1)Unigine (1)умные колонки (1)сварка (1)смена деятельности (1)смена профессии (1)рабочие визы (1)прототипы (1)okama (1)ленты (1)посты (1)сообщества (1)автозапуск (1)Акселератор полезных игр (1)инженер (1)недоразумение (1)3d-визуализация (1)LGTM (1)процессы управления (1)wear os (1)64bit (1)32bit (1)требование (1)нативный код (1)Time Capsule (1)Apple Filing Protocol (1)сетевое хранилище (1)Летние школы (1)салоны связи (1)fba (1)нефть (1)поколение z (1)перерыв (1)сто (1)сергей ляджин (1)учебники (1)письмо (1)macbook m5 (1)подержанные товары (1)ОРД (1)маркировка рекламы (1)карпаты (1)запуск (1)змейка (1)tech show (1)tech media (1)ИИ-кассир (1)кафе (1)inno clouds (1)общепит (1)horeca (1)adversa (1)8bitdo (1)механические клавиатуры (1)digital humans (1)виртуальные аватары (1)CAC (1)маркировка контента (1)gemini api (1)Flex Inference (1)Priority Inference (1)production (1)latency (1)cost optimization (1)leo (1)командная работа (1)ошибки в проектах (1)РАТЭК (1)uwms (1)отходы (1)zhipu ai (1)фрагментация интернета (1)налоги на софт (1)новости облаков (1)lightning (1)sony interactive entertainment (1)cinemersive (1)false positive (1)ии модель от netflix (1)нетфликс (1)нейросеть netflix (1)OpenSSH 10.3 (1)openssh 10 (1)OpenSSH (1)Conway (1)главный научный сотрудник (1)Болливуд (1)киноиндустрия (1)AI filmmaking (1)дубляж (1)NeuralGarage (1)Galleri5 (1)sheets (1)стиральные машины (1)стирка (1)японский язык (1)рабочая виза (1)внж (1)пользовательское соглашение (1)дисклеймер (1)отказ от ответственности (1)фанфики (1)трансформаторы (1)накрутка голосов (1)ток-шоу (1)meshoptimizer (1)meshoptimizer 1.1 (1)Netrunner 26 (1)Netrunner (1)asset (1)package (1)gemini live (1)онлайн-магистратура (1)fps (1)частота кадров (1)магазины игр (1)Qmmp 2.3.2 (1)walker s2 (1)научный сотрудник (1)Wine 11.6 (1)полярон (1)СибГУТИ (1)плата разработчика (1)очки будущего (1)светотерапевтические очки (1)Blue Sky Pro (1)СамГМУ (1)решетнёв (1)nanocode (1)стопборщевик (1)шад (1)борщевик сосновского (1)офисный пакет (1)промптхаб (1)check point (1)убыток (1)финансовые результаты (1)QuickView 5.0.0 (1)HWMonitor 1.63 (1)пакет мер (1)trueconf (1)samsung messages (1)трапнспорт (1)редактирование видео (1)RapidRAW 1.5.3 (1)новосибирск (1)метро (1)нгу (1)планирование смен (1)phishing (1)phishing protection (1)f6 (1)покрытие сети (1)drive test (1)HopChain (1)hive0117 (1)darkwatchman rat (1)вредоносные рассылки (1)защита электронной почты (1)business email protection (1)дбо (1)terms of use (1)юридические риски (1)hallucinations (1)листинг (1)Sakana AI (1)Stellarium 26.1 (1)Stellarium 26 (1)stellarium (1)курьерская служба (1)курьерская доставка (1)трейлер (1)комиссия продавцов (1)китайские магазины (1)китайские товары (1)смартфоны и коммуникаторы (1)смартфоны и планшеты (1)репетиторство (1)превышение скорости (1)ограничение скорости (1)колорадо (1)positive technologies (1)имущество (1)наследство (1)reactjs (1)artemis 2 (1)no-code-конструктор (1)bpm (1)сэд (1)начало карьеры (1)начало карьеры в it (1)студенты it (1)отбор на стажировку (1)программа стажировки (1)buisness (1)многоразовые ракеты-носители (1)tianlong-3 (1)землеустройство (1)комплект nanocad (1)трейдер (1)opensearch (1)cloudwards (1)цензура интернета (1)свобода интернета (1)телекоммуникационное оборудование (1)мфти телеком (1)Home Cinema 2.7.0 (1)bitchat (1)Bots (1)страны (1)свобода (1)PeaZip 11.0 (1)486 (1)Medvi (1)msi titan (1)titan (1)opencloud (1)Claude Code утечка исходников (1)Anthropic DMCA (1)OpenClaw блокировка (1)Qwen 3.6-Plus (1)Claw Code Rust (1)Phosh 0.54.0 (1)google ai edge eloquent (1)расшифровки (1)транскрипция (1)сетевая методитка (1)MVNO (1)сбермобайл (1)Альфа мобайл (1)т-мобайл (1)пользовательский опыт (1)диктовка (1)подготовка команд (1)защита инфраструктуры (1)hr-аналитика (1)goodt (1)turbo (1)материалы для педагогов (1)день космонавтики (1)e OS 3.6 (1)rca (1)провода (1)шнуры (1)качество звука (1)retailtech (1)retail (1)стенд (1)lentatech (1)налог на роботов (1)Public Wealth Fund (1)четырехдневная рабочая неделя (1)ЦТФ (1)Альфа ЦТФ (1)флаг (1)тест-план (1)tms (1)коучи (1)тренининги (1)hr-менеджер (1)finedayonline (1)fineday (1)fanruan (1)ИИ-блендер (1)блоки (1)годовой доход (1)конфиденциальная информация (1)запросы (1)browserstack (1)apollo (1)статус java (1)статус java 2026 (1)удаление файлов (1)корзина (1)локальное хранилище (1)пдн (1)дорожные камеры (1)MemPalace (1)LongMemEval (1)AAAK (1)комментирование (1)Neural Materials (1)визуальные галлюцинации (1)рабочие места (1)Rocket 1.0 (1)разработка продуктов (1)юнит-экономика (1)конкурентная разведка (1)pixel 8 pro (1)p8p (1)больница (1)базис (1)акола (1)золотой сайт (1)венчурный фонд (1)Zero Shot (1)vibe-кодинг (1)digital twins (1)Generalist AI (1)GEN-1 (1)законы масштабирования (1)сорбенты (1)разлив нефти (1)длинный горизонт (1)векторная база данных (1)GPU ядра (1)квантовая пена (1)редкоземельные металлы (1)playstation studios (1)персонажи (1)gran turismo 7 (1)vulnerability detection (1)иртея (1)базовые станциии (1)a18 pro (1)playwright (1)n8n (1)radeon rx 6950 xt (1)сборка пк (1)PaintFE (1)Rust Coreutils 0.8.0 (1)Solod (1)однородность (1)Grok 4 (1)it-право (1)юридические вопросы (1)архитектурные подходы (1)sony pictures (1)spe (1)аудит доступа (1)ред адм (1)роботизация процессов (1)VoxCPM2 (1)мультиязычные аудиоданные (1)THUNLP (1)OpenBMB (1)codin-agent (1)DeepPavlov (1)токсичность (1)туннельный эффект (1)Yandex SIEM (1)логи (1)audible (1)Local Guides (1)пользовательский контент (1)captions (1)Safety Fellowship (1)безопасность в сети (1)оценка уязвимостей (1)снижение рисков (1)слепые люди (1)шрифт брайля (1)видеосвязь (1)fakenews (1)судебная ошибка (1)критическое мышление (1)Graviton (1)Trainium3 (1)ИИ-сектор (1)производители чипов (1)технологическая блокада (1)возгорание (1)перепродажа (1)playstation one (1)материнская плата (1)microsd (1)дисковод (1)kindle touch (1)kindle paperwhite (1)petka (1)tcpip (1)приемная кампания (1)абитуриенты (1)KarpathyTalk (1)акит (1)оповещение (1)Grab (1)ride-hailing (1)достовка (1)суперприложение (1)индонезия (1)group ride (1)Юго-Восточная Азия (1)общая папка (1)преформы (1)завод (1)саранск (1)мордовия (1)vk видео премиум (1)grande (1)вднх (1)Космическое образование (1)astra linux special edition (1)редактирование фотографий (1)tantor xdata (1)xdata (1)oracle exadata (1)сетевое подключение (1)аврора (1)российские автомобили (1)AI модели для разработки (1)генерация кода AI (1)Zhipu AI GLM (1)LLM для программистов (1)AI в IDE (1)AI инструменты разработчика (1)oumi (1)sandisk (1)sd-карты (1)HappyHorse (1)юургу (1)moto g stylus (1)moto pad (1)GPU оптимизация (1)бенчмарки ИИ (1)сетевые органичения (1)роботизация складов в россии (1)rms (1)Октава-дм (1)дискуссионная система (1)OCS-80 (1)steam link (1)amr (1)человекоцентричность (1)HREXPO PRO Людей (1)Claude Managed Agents (1)bughunting (1)CompressO 3.0.0 (1)Glow 26.6 (1)APT 3.2.0 (1)advanced package tool (1)VeraCrypt (1)wireguard (1)muse (1)skoda (1)велосипедный звонок (1)звонок (1)duobell (1)world leaks (1)лос-анджелес (1)гиппокамп (1)FTL1 (1)SteamGPT (1)провайдеры связи (1)отпуск (1)лечение (1)уход за больными (1)отгул (1)мышки (1)cad-файлы (1)AI-платформы (1)анимация и 3d графика (1)самостоятельный ремонт (1)минэк (1)остин (1)avride (1)утка (1)животные (1)LFM2.5-VL-450M (1)Vision Language Models (1)Jetson Orin (1)сегнетоэлектрическая память (1)микрочипы (1)нейроморфные системы (1)никнейм (1)юзернеймы (1)приложения в ChatGPT (1)Fox (1)entertainment (1)исскуственный интеллект (1)ovhcloud (1)defense (1)NATO (1)sovereign cloud (1)поиск фильмов (1)сатоши накамото (1)bitcoin (1)опровержение (1)саппорт (1)руководство командой (1)развитие персонала (1)java митап (1)шаги (1)GPT-6 (1)тендеры (1)vimrag (1)vrag (1)зумер (1)legend of future past (1)mud (1)mongodb (1)джон радофф (1)iphone air 2 (1)PT Email Security (1)почтовый шлюз (1)песочница (1)массовые атаки (1)ии-аватары (1)кластеризация (1)ред софт (1)dbrain (1)ai-agentic platforms (1)fintech 2026 (1)john deere (1)сельскохозяйственное оборудование (1)meet (1)перевод речи (1)mig a65 (1)плейтест (1)ии-подписки (1)chatgpt codex (1)советник (1)ии-оркестрация (1)claude advisor (1)zte (1)умный экран (1)Эдуард Успенский (1)ИИ-мультфильмы (1)ON Media (1)Shutter Encoder 20.0 (1)freebsd foundation (1)обнаружение (1)ускорение видео (1)push-уведомления (1)звёздные машины (1)сфера дайсона (1)свиноводство (1)фермы (1)ремонт дорог (1)GParted Live 1.8.1-3 (1)GParted Live (1)Xeon (1)ipu (1)Sierra (1)Bret Taylor (1)Ghostwriter (1)natural language (1)Agents Transport System (1)внедрение (1)политики доступа (1)pam-система (1)Cohere (1)Aleph Alpha (1)суверенный AI (1)finnext (1)комментарии (1)редактирование (1)Неделя космоса (1)Кадры для космоса (1)кампании (1)svg (1)интернет-магазины (1)magento (1)esu (1)ltsb (1)windows 10 enterprise (1)opensource (1)бесплатная лицензия (1)бесплатный интернет (1)аа (1)компетенции (1)банки казахстана (1)ученики (1)RKS Global (1)администраторы (1)GitButler (1)Скотт Чакон (1)Series A (1)a16z (1)version control (1)merge conflict (1)Qwen-3.6 (1)кастомные чипы (1)AI infrastructure (1)изучение луны (1)cpuid (1)почта mail.ru (1)advisor tool (1)мультиагентность (1)оркестрация агентов (1)малые космические системы (1)сухая вода. (1)nintendo wii (1)брайан келлер (1)claude for word (1)дополнения word (1)ultraplan (1)AeroFTP (1)авиадиспетчеры (1)msix (1)утилиты для windows (1)соц.сети (1)трекинг движений (1)машинное зрение (1)болезнь (1)выдумка (1)StopAI (1)Little Snitch (1)ставки на спорт (1)Calibre 9.7 (1)sifive (1)Clouflare (1)xslt (1)GNU nano 9.0 (1)GNU nano (1)nano (1)гагарин (1)управление зависимостями (1)repository (1)артефакты (1)стэнфорд (1)стэнфордский университет (1)минюст (1)генпрокуратура (1)нежелательная организация (1)нежелательные организации (1)Lite Catalog (1)gadhouse (1)miko (1)кассетный плеер (1)плеер (1)аудиокассеты (1)amazon luna (1)игровые сервисы (1)стриминг игр (1)SQLite 3.53 (1)sqlite (1)youtube music (1)Косионавт (1)поехали (1)red hat china (1)машина (1)altera max (1)fpga altera (1)срок службы (1)нарушения зрения (1)голосовые технологии (1)вербализация (1)altsendme (1)perl (1)тимбилдинг (1)корпоративы (1)цифровой банкинг (1)клиентский опыт (1)продуктовый дизайн (1)kodi (1)xbmc (1)mediacenter (1)медиацентр (1)медиаплеер (1)тв-приставка (1)HumanX (1)капитал (1)спецсимволы (1)распознавание эмоций (1)плис (1)плюс гейминг (1)маркетплейс ruvds (1)одобрение (1)Microsoft Edge 147 (1)iaas (1)gpu вычисления (1)шантаж (1)геймплей (1)социальные службы (1)прохождение игры (1)роботизация бизнес-процессов (1)NEC (1)трансмиссия (1)космонавт (1)учёный (1)переход на linux (1)b1 (1)витамины (1)battle net (1)локация (1)регион (1)fat32 (1)форматирование (1)форматирование памяти (1)новичкам (1)статьи на хабр (1)смерть (1)ai аватары (1)системный аналитик (1)системный аналитик навыки (1)риск (1)Диагностика-М (1)интраскоп (1)samsung magician (1)Trisquel 12.0 (1)Trisquel (1)Servo 0.1.0 (1)unitree h1 (1)h1 (1)будущее (1)tiled layout (1)агентная разработка (1)changelog (1)appscreener (1)Anthropic Managed Agents (1)Advisor Strategy Opus Sonnet (1)Meta Muse Spark (1)Artificial Analysis Index (1)MiniMax M2.7 open weights (1)GLM-5.1 MIT (1)Ollama Cloud подписка (1)Claude Code adaptive thinking (1)окр (1)ипохондрия (1)тревога (1)психические расстройства (1)автоматизация предприятий (1)онбординг (1)Engramme (1)discourse (1)файловая система (1)яндекс тв станция (1)оцифровка видео (1)сохранение музыки (1)стартаперы (1)рабочий день (1)график работы (1)архитектура системы (1)непрерывность (1)антихрупкость (1)infrastructure-as-a-code (1)2030 (1)wbce (1)стенды (1)bms (1)Wiren Board (1)реле (1)вакцинация (1)чтение файлов (1)конвейер разработки (1)digital q (1)платформенный подход (1)mes-системы (1)управление производством (1)киберустойчивость (1)поиск по фото (1)cue (1)cue7 (1)работа аналитика (1)fullstack development (1)ozon tech (1)системная аналитика (1)outlook lite (1)outlook mobile (1)Waveshare (1)PocketTerm35 (1)кпк (1)ограничения интернета (1)unicorn (1)майкрософт рус (1)watt (1)watt studio (1)tsarevna (1)trains electrostorm (1)балетный слэшер (1)слэшер (1)x2d (1)bambu lab x2d (1)киногео (1)венера (1)былина (1)far far games (1)action-rpg (1)процедурная генерация (1)изображений (1)водяные знаки (1)mission 1 (1)booking.com (1)бронирование отелей (1)pfcksum (1)DaVinci Resolve 21.0 (1)DaVinci Resolve (1)CopyQ 15.0 (1)nginx 1.30.0 (1)nginx 1.30 (1)GPT-5.4-Cyber (1)Тая (1)gen-t (1)антифрод-системы (1)средства защиты (1)routines (1)инженерные процессы (1)solar inrights (1)акустические атаки (1)идентификатор (1)action (1)онлайн (1)galaxy watch (1)разрядка (1)3d-карты (1)картография (1)data leaks (1)андеграунд (1)mobile development (1)мобильные устройства (1)веб-игра (1)AI-интерфейсы (1)поиск в операционной системе (1)контекстный поиск (1)OpenBGPD 9.1 (1)OpenBGPD 9 (1)OpenBGPD (1)office 2021 (1)ltsc (1)проприетарное по (1)java 26 (1)poll (1)раскладушки (1)раскладушка (1)seres (1)aito (1)унитаз (1)автомобильный туалет (1)nanoNODE (1)визуальное программирование (1)экосистема nanoCAD (1)бизнес-планирование (1)ibp-платформа (1)optimacros (1)бизнес-моделирование (1)тепловая карта продуктивности (1)альтернатива Todoist (1)google takeout (1)globalstar (1)поиск файлов (1)Sniffnet 1.5.0 (1)Sniffnet (1)free (1)pay (1)mac neo (1)Ising (1)Nothing warp (1)raspberry pi os (1)passwordless (1)одноплатник (1)cookie (1)куки (1)OpenSSL 4.0.0 (1)OpenSSL (1)NetSpeedTray 1.3.0 (1)TagTinker (1)Electronic Shelf Labels (1)Harvey (1)проприетарная лицензия (1)планирование проектов (1)windows recall (1)boston dynamics (1)spot (1)gemini robotics (1)маршрут (1)распознавание паспорта (1)распознавание документов (1)подделка документов (1)лента (1)видеосервисы (1)redos (1)регулярные выражения (1)ipvs (1)ietf (1)черновик (1)htop 3.5.0 (1)htop (1)open vswitch (1)l3 (1)dpdk (1)bpf (1)xdp (1)бэкдоры (1)российская орбитальная станция (1)рос (1)glitch boy (1)глитчи (1)синтезаторы (1)melted electronics (1)чиптюн (1)видеоарт (1)мощные сервера (1)видеосервер (1)финансисты (1)закон о приземлении (1)набор сотрудников (1)коллекторы (1)онлайн-банкинг (1)офисы (1)дистанционное обслуживание (1)антенны связи (1)Linux 7 (1)Baikal-T1 (1)Baikal (1)методы ввода (1)owasp (1)standoff17 (1)кибербитва (1)blueteam (1)государство f (1)standoff 365 bug bounty (1)свайп (1)руки (1)физическая активность (1)судья (1)информацинные технологии (1)TTS (1)голосовые модели (1)управление голосом (1)HWiNFO 8.46 (1)железные дороги (1)окна (1)антенны (1)звукоизоляция (1)скоростные поезда (1)иви (1)два экрана (1)e-in (1)huawei mobile services (1)huawei enterprise (1)huawei mate xs (1)huawei nova 15 (1)youtubr (1)google one (1)veai (1)rnd (1)подкасты для разработчиков (1)osmo pocket (1)dji ocmo pocket (1)osmo pocket 4 (1)съёмки (1)н-1 (1)снимки (1)архив (1)ссср (1)биодизайн (1)дума (1)блокировка аккаунта (1)неподдерживаемое местоположение (1)AI-сервисы (1)доступ из России (1)безопасность аккаунта (1)Zorin OS 18.1 (1)Zorin OS 18 (1)Zorin OS (1)GNOME 50.1 (1)analytics (1)петербург (1)ab-тестирование (1)обнаружение вредоносного по (1)bytedog (1)лайфкодинг (1)модули (1)nanocad bim строительство (1)производство оборудования (1)библиотека компонентов (1)инженерия программного обеспечения (1)база данных оборудования (1)клипы (1)intel core ultra 200hx (1)бесшумный компьютер (1)email service (1)мечтай по-крупному (1)онлайн-кредиты (1)ollama (1)цифровое проектирование (1)геораспределенность (1)garbage collector (1)incremental gc (1)wi-fi роутер (1)точка доступа (1)точка доступа wi-fi (1)переполнение буфера (1)google ai mode (1)jira service desk (1)умный поиск (1)цикл разработки (1)zephir (1)client (1)европол (1)операция (1)мобильная ос (1)использование памяти (1)корпоративный портал (1)автоматизация сервиса (1)корпоративные сервисы (1)shardman (1)шардирование (1)шадринг (1)ракета-носитель воронеж (1)восход (1)росоксмос (1)цниимаш (1)майк кригер (1)RIGF (1)рунити (1)опрос персонала (1)социнжиниринг (1)социальные сервисы (1)рекламная компания (1)эмма танг (1)венкат венкатарамани (1)Rust 1.95 (1)Proton 11.0 (1)11.0 Beta 1 (1)RAM-диск (1)социологическое исследование (1)пересказы (1)аннотации (1)годзилла (1)спойлеры (1)Vidoc Security (1)pixelsocieties (1)специальные символы (1)similarweb (1)антенно-мачтовые сооружения (1)амс (1)антены (1)башни (1)антенная система (1)подсистемы (1)research (1)Elephant Alpha (1)stealth-модель (1)бесплатные AI модели (1)function calling (1)бенчмарки LLM (1)лазер (1)обледенение (1)расширения chrome (1)расширения для браузеров (1)алиса про (1)яндекс почта (1)майкл труэлл (1)бенчмаркинг (1)бенчмарк кода (1)Консорциум печатных плат (1)рту (1)Scale AI (1)джеты (1)Cygnus X-1 (1)lyra 2.0 (1)firefly ai assistant (1)project moonlight (1)Podroid (1)podman (1)Wine 11.7 (1)WireGuard для Windows 1.0 (1)WireGuardNT 1.0 (1)лицо (1)worldcoin (1)кикстартер (1)nica (1)ледокол (1)X5 Tech (1)полумарафон (1)вкалывают роботы (1)LibreSSL 4.3.0 (1)LibreSSL (1)CSVMusic (1)Gitea 1.26 (1)Kaiten (1)кайтен (1)nvidia geforce (1)rtx 4060 ti (1)оптовая торговля (1)регистрация IMEI (1)fog data (1)teradici pcoip (1)remote graphics software (1)хьюстон (1)даллас (1)ssd-накопители (1)nvme ssd (1)спикер (1)клевета (1)облачная разработка (1)context.ai (1)платная версия (1)минимализм (1)российское железо (1)серверная память (1)регистровая память (1)rdimm (1)утилизация (1)академия нанософт (1)3-d графика (1)обучение инженерии (1)начертательная геометрия (1)жку (1)минстрой (1)коммунальные платежи (1)adobe premiere (1)цветокоррекция (1)tesla x (1)выбросы углекислого газа (1)c2b (1)финансы для всех (1)блокировки сайтов (1)пиратский контент (1)wild gunman (1)автоматы (1)реконструкция (1)вестерны (1)электромеханическая аркада (1)вояджер-1 (1)fintool (1)уфа (1)emudeck (1)playnix (1)компактные пк (1)компактные компьютеры (1)игровые компьютеры (1)холодильники (1)холодильник (1)русское географическое общество (1)нейросеть никола (1)статическийанализ (1)архитектура по (1)architecture-as-code (1)itunes (1)uber eats (1)возврат товара (1)open source AI (1)multi-agent (1)скат (1)stingray (1)power 1000 mini (1)элементы питания (1)джон тернус (1)Firefox 150 (1)Denuvo Anti Tamper (1)академия usergate (1)почасовая оплата (1)qt creator (1)верификация возраста (1)ирландия (1)скорость работы (1)смена батареи (1)электронные отходы (1)синтез голоса (1)железо и технологии (1)ит-образование (1)моделирование бизнес-процессов (1)бизнес-информатика (1)сбор (1)500 рублей (1)seiko usa (1)shopify (1)ири (1)Данилов (1)клиенты (1)saas-сервис (1)экран (1)монитор (1)панель (1)визуальные эффекты (1)AI coding assistant (1)локальный инференс (1)LXQt 2.4.0 (1)lxqt (1)vitalink (1)ретушь фотографий (1)пиратские сайты (1)mastodon (1)active directory (1)icap (1)x.509 (1)sftp (1)волоконно-оптическая связь (1)agentic web (1)spring data (1)конференция про ии (1)itsm-система (1)сервис деск (1)Silent Hill 2 (1)тсд (1)оснащение (1)бесплатное обучение ит (1)образование для студентов (1)курсы для старшеклассников (1)практико-ориентированное обучение (1)менторство в ит (1)junior (1)ofcom (1)Pioner (1)gfa games (1)задолжность (1)корпусирование чипа (1)мипромторг (1)osmo (1)лазеры (1)рабочие переписки (1)скуд (1)hitachi (1)android studio (1)CubeSandbox (1)изоляция (1)Git 2.54 (1)Mozilla Thunderbird 150 (1)мобильная сеть (1)охрана периметра (1)охрана предприятий (1)охрана домов (1)ОПС (1)стилер (1)дюп (1)jar (1)weedhack (1)Anthropic подписка (1)AI инструменты для разработчиков (1)цены на AI (1)агентное программирование (1)Qwen3.6 35B-A3B (1)Codex macOS (1)OpenAI Agents SDK (1)Prompt Requests (1)xhigh reasoning (1)блокировщик рекламы (1)удалённые рабочие места (1)удалённые столы (1).net (1)game pass (1)pc game pass (1)xbox game pass (1)xbox game pass ultimate (1)Home Cinema 2.7.1 (1)милан (1)умная лампа (1)tracker (1)SourceCraft CLI (1)цифровые системы (1)тренинги (1)корпоративное обучение (1)платформенная экономика (1)интеграция сервисов (1)интеграция систем (1)интеграция приложений (1)digital q.integration (1)бесплатный дистрибутив (1)пламмер (1)диспетчер задач (1)центральный процессор (1)показатели (1)нагрузка (1)нагрузка на процессор (1)резак (1)кабель связи (1)подводные коммуникации (1)судно (1)испытание (1)студенты в it (1)fmc (1)воображение (1)восприятие (1)Oracle VirtualBox 7.2.8 (1)Oracle VirtualBox (1)VirtualBox 7.2.8 (1)VirtualBox (1)deckhouse kubernetes platform (1)deckhouse virtualization platform (1)dkp cse (1)страховое мошенничество (1)камеры видеонаблюдения (1)страховая компания (1)quck assist (1)арт-директор (1)технические специалисты (1)разряд (1)громкость (1)вкладки браузера (1)росфинмониторинг (1)latitude (1)voyage (1)rpg (1)текстовые игры (1)okcupid (1)typescript 7 (1)multidirectory (1)икусственный интеллект (1)polymega remix (1)polymega (1)playmaji (1)классическая литература (1)mic mini 2 (1)dji mic (1)микрофоны (1)TPU v8 (1)повестка (1)алмазы (1)PRET (1)онкология (1)знаменитости (1)QEMU 11.0 (1)WSL9x (1)белый список VPN (1)сетевая блокировка (1)Linux 6.19 (1)Linux 6.19.13 (1)Linux 6 (1)Медиаискусство (1)технологическая олимпиада (1)клиентская оптимизация (1)маркетинговая стратегия (1)Дурикович (1)шифровальщики (1)теневой интернет (1)продажа доступов (1)чистая комната (1)активность мозга (1)подмена данных (1)Сбер2В (1)тор (1)термометр (1)push (1)тарифы мтс (1)игровые клубы (1)zbook (1)universal print (1)microsoft graph (1)общие папки (1)общий доступ (1)google cloud next (1)криптобиржи (1)хакерская атака (1)AI-сервер (1)8U (1)lada vesta (1)судебные разбирательства (1)американ макги (1)quake (1)unix (1)iterm2 (1)команды (1)выполнение произвольного кода (1)псевдотерминал (1)терминалы (1)назад (1)рейтинг сайтов (1)активация windows (1)код активации (1)atlas pro (1)коврик (1)коврик для мыши (1)коврик для мышки (1)Privacy filter (1)qualcomm snapdragon (1)bootrom (1)чип (1)ai assistant (1)сравнение производительности (1)РВФ (1)венчурные инвестиции (1)Ubuntu 26.04 LTS (1)Ubuntu 26 (1)кодирование (1)qclaw (1)dji lito (1)lito x1 (1)lito 1 (1)wildcat lake (1)Command Finder (1)Tails 7.7 (1)Nuitka 4.0 (1)Nuitka (1)pentest (1)pentesters (1)redteaming (1)killchain (1)асутп (1)V4-Pro (1)V4-Flash (1)открытые модели (1)MIT-лицензия (1)когерентность (1)книга рекордов гиннесса (1)стратосфера (1)аэростат (1)обмен фотографиями (1)моментальные снимки (1)широкополосный интернет (1)VPN в России (1)блокировка VPN (1)ViPNet (1)удалёнка 2026 (1)фотонный процессор (1)плазмоника (1)vk donut (1)угольная электростанция (1)ископаемое топливо (1)куру (1)gchq (1)ncsc (1)displayport (1)линза (1)наноструктуры (1)стереоскопические изображения (1)метаповерхность (1)новости it (1)новости ии (1)настольный теннис (1)sony ai (1)лосось (1)арбитраж (1)loveable (1)bola (1)jpoint (1)heisenbug (1)автоматическое тестирование (1)jug.ru (1).us (1)fujinet (1)турция (1)sccm (1)25h2 (1)Ловител (1)биобанки (1)песня (1)слайсеры (1)грибки (1)mbse (1)Системная инженерия (1)проектирование систем (1)принятие решений (1)togaf (1)system engineering (1)system design (1)FreeRDP 3.25 (1)xchat (1)шифры (1)наркотики (1)похищение людей (1)kingston (1)есиа (1)RapidRAW 1.5.4 (1)url (1)pragmata (1)resident evil (1)capcom (1)SyntheMol-RL (1)claude haiku 4.5 (1)разработка игры (1)создание игр (1)ии в играх (1)nike (1)маршрутизатор (1)програмисты (1)rtx 5070 ti (1)qwen image 2.0 pro (1)гарвардская школа бизнеса (1)расширения для google chrome (1)бен хорвиц (1)айдол (1)aidol (1)липсинк (1)QuickView 5.3.0 (1)задачи эрдёша (1)лиам прайс (1)аудиотехника (1)аудиоинтерфейсы (1)zoom video communications (1)zoom corporation (1)спасатели (1)кэт ву (1)fomo (1)эллиптическая криптография (1)ecc (1)онлайн-торговля (1)код будущего (1)генная терапия (1)глухота (1)fda (1)deepseek ai (1)deepseek v4 pro max (1)генеративный контент (1)Ars Technica (1)ядерные технологии (1)ядерные реакторы (1)terrapower (1)Cat Gatekeeper (1)устная речь (1)пандемия коронавируса (1)turtle beach (1)активное шумоподавление (1)yandex research (1)книжная конструкция (1)гибко-жесткая печатная плата (1)научные фонды (1)netgear (1)Fwupd 2.1.2 (1)палеонтология (1)неандертальцы (1)BleachBit 6.0.0 (1)BleachBit (1)Ethernet-драйверы (1)chatgpt 5.3 codex (1)chatgpt codex-1 (1)chatgpt o3 (1)chatgpt atlas (1)сторм данкан (1)Toyota Crown (1)кресло (1)ГигаАкадемия (1)disneyland (1)iphone 17 (1)usb-a (1)яндекс фабрика (1)оффлайн-магазин (1)кэш (1)implicit conversions (1)syrup (1)friendster (1)поиск друзей (1)lepton (1)Роса Мобайл 3.0 (1)иностранный капитал (1)rail (1)аудиоданные (1)S3 Virge DX 4MB (1)state of devops (1)state of cloud native (1)затраты (1)бюджеты компаний (1)R-EVOlution Conference (1)мониторинг безопасности (1)eps (1)overview energy (1)Speech-to-LaTeX (1)датасет (1)latex (1)математические формулы (1)Audio-LLM (1)asr (1)телекоммуникации (1)геозоны (1)ограбление (1)luxmsbi (1)сертификат (1)t-pay (1)энергетическая инфраструктура (1)tesla robotaxi (1)мобильные процессоры (1)ии-смартфон (1)lapsu$ (1)голосовые данные (1)сэмплы (1)цензура в интернете (1)нко (1)udaff.com (1)пресссссссс фффф (1)cloud infrastructure (1)managed kubernetes (1)managed kubernetes cluster (1)собаки (1)взлом роутера (1)лицемерие (1)banana pi (1)платы (1)MULTIGOODS (1)Dillo 3.3.0 (1)Dillo (1)symphony (1)afp (1)smb (1)сетевые протоколы (1)tls 1.2 (1)tls 1.3 (1)Qwen 3.6 27B (1)Cursor xAI (1)computer vision (1)индикатор загрузки (1)индикаторы (1)элементы дизайна (1)сотовые вышки (1)перехват сигнала (1)переключение (1)опции (1)usage-based billing (1)тарификация (1)агентные режимы (1)мультипликаторы моделей (1)оплата по использованию (1)автодополнение кода (1)Copilot code review (1)ИИ-инструменты для разработки (1)платиновый партнер (1)единое информационное пространство (1)объединенные коммуникации (1)приложение для ios (1)tls 1.0 (1)tls 1.1 (1)tls-соединение (1)Kandinsky 6.0 Image (1)объём (1)строки кода (1)разработка linux (1)разборка (1)ремонт своими руками (1)AI FinOps (1)облачные расходы (1)ELMUR (1)внешняя память (1)MIKASA-Robo (1)T-Maze (1)защищенное облако (1)Project Maven (1)автономное оружие (1)массовое наблюдение (1)AI governance (1)закрытые модели (1)магистральные операторы (1)реформа (1)дц (1)самара (1)garmin (1)windows shell (1)CVE-2026-32202 (1)хакерство (1)mobile device management (1)пчёлы (1)счёт (1)bdui (1)дизайн-система (1)вечеринка (1)аренда роботов (1)umserv (1)веб-студия (1)разработка сайтов (1)Запароленные архивы (1)информационная безопасность и сети (1)autodesk fusion (1)adobe creative cloud (1)splice (1)canva affinity (1)sketchup (1)гражданское общество (1)школа дизайна (1)dsgn sense (1)ask youtube (1)чипирование питомцев (1)fail2drive (1)автопилоты (1)DuctGPT (1)GPT-2 (1)браузерные расширения (1)Centauri Carbon (1)гибридная работа (1)возвращение в офис (1)AnyDesk 9.7.1 (1)crypto-gost (1)affinity (1)7-Zip 26.01 (1)7-Zip 26 (1)7-Zip (1)phoenix (1)микропрограммное обспечение (1)big picture (1)vimeo (1)snowflake (1)bigquery (1)видеоплатформа (1)Nemotron 3 Nano Omni (1)среда разработки (1)кабель питания (1)датчик температуры (1)перегрев (1)Demis PRO (1)AI в маркетинге и продажах (1)tin can (1)выставка иннопром ташкент (1)ташкент ИТ (1)экономика средняя азия (1)ядерный реактор (1)ядерная энергия (1)ядерная энергетика (1)программист (1)GPU VK Cloud (1)благотворительность (1)ясный язык (1)интернет в самолете (1)ifc (1)vmware esxi (1)пермский политех (1)бурение (1)геофизика (1)горизонтальные напряжения (1)скважины (1)гидроразрыв (1)репетитор (1)репетитор математика (1)ASE (1)чиплеты (1)упаковка чипов (1)amazon shopping (1)описание товаров (1)Scout AI (1)Fury (1)автономная техника (1)DARPA (1)defense tech (1)photoshop (1)galax (1)palit (1)рыбы (1)обработка документов (1)рефераты (1)тестирование гипотез (1)комфорт для глаз (1)мигрень (1)SMS-RAT (1)мыши (1)нос (1)запах (1)качество (1)postmortem (1)инженерная культура (1)произношение (1)factorio (1)Administratorio (1)стратегии (1)бюрократия (1)proptech (1)криптообменник (1)криптообменники (1)государство (1)mayo clinic (1)REDMOD (1)s3 (1)linstor (1)GPT-5.1 (1)ухань (1)покупка игр (1)активация (1)Cursor SDK (1)однокнопочная клавиатура (1)86-dos (1)pc-dos (1)email-интеграция (1)philips (1)освещение (1)умное освещение (1)Аккофриск (1)данные здоровья (1)персонализированная медицина (1)анонимизация (1)wearable data (1)Roze AI (1)автономные роботы (1)серверные фермы (1)Smart Engines (1)Smart Document Engine (1)цифровые документы (1)born-digital (1)wiz (1)git push (1)размер (1)Space VDI (1)ктр (1)zwift (1)rouvy (1)велотренажер (1)велотренировки (1)ит-конференции (1)роскачество (1)pixel 9a (1)сервисный центр (1)опасность (1)ассоциации (1)Ассоциация разработчиков СУБД (1)RuDB (1)the edgers (1)ps5-linux (1)микшерный пульт (1)вгтрк (1)финансовый учет (1)платежи за рубежом (1)телетрап (1)высокоточные комплексы (1)авиация (1)смешанная реальность (1)системные приложения (1)педагогическая конференция (1)уязвимости и их эксплуатация (1)sap npm (1)инфостилеры (1)commodore (1)commodore c64c ultimate (1)open api (1)cname (1)перехват доменов (1)EA Sports FC (1)fifa (1)хотспоты (1)телевизор (1)особо значимый проект (1)мицифры (1)горячие линии (1)входящие вызовы (1)штаб-квартира (1)токенизатор (1)токенизаторы (1)CVE-2026-31431 (1)квантовая телепортация (1)микрофон (1)октава (1)МК-019 (1)некастодиальный кошелёк (1)жесты (1)управление роботом (1)мгту станкин (1)дгту (1)определители номера (1)commodore 64 (1)ретрокомпьютер (1)gen z (1)gallup (1)критика ИИ (1)Zed 1.0 (1)AIDA64 8.30 (1)спутниковое оборудование (1)whm (1)перехват данных (1)проводник windows (1)прокрутка (1)Cloudflate (1)гигабитный интернет (1)домашние системы. (1)маркировка товаров (1)црпт (1)усманов (1)Zulip 12.0 (1)Zulip (1)reactos (1)GameNetworkingSockets 1.5.0 (1)GameNetworkingSockets (1)agentic commerce (1)Shared Payment Token (1)виртуальные карты (1)автономные ассистенты (1)yubico (1)yubikey (1)аппаратные ключи (1)Advanced Account Security (1)GenAI.mil (1)V1 Atomic Heart Edition (1)микрофоны союз (1)Одк стар (1)доставщик (1)WinRAR 7.21 (1)WinRAR (1)RAR 7.21 (1)RAR (1)RAR 7 (1)Wireshark 4.6.5 (1)Amjad Masad (1)Superintelligence Labs (1)self-learning (1)whole-body control (1)legal tech (1)Westlaw AI (1)Thomson Reuters (1)AI-галлюцинации (1)ответственность (1)комплаенс (1)DietPi 10.3 (1)widelux (1)wideluxx (1)silverbridges (1)panon (1)предупреждение безопасности (1)oled-дисплей (1)портативность (1)ps5 slim (1)Shotcut 26.4 (1)ближний восток (1)бахрейн (1)Ммтс (1)common crawl (1)дефицит электроники (1)цифровая техника (1)ограничение ввоза (1)фиксированный интернет (1)региональные ограничения (1)Рунет (1)Calibre 9.8 (1)GCC 16.1 (1)GCC 16 (1)gcc (1)NetHack 5 (1)NetHack (1)NetHack 5.0.0 (1)шрифты (1)фанатская разработка (1)моноширинный шрифт (1)сжатие видео (1)спецификации (1)сторонние приложения (1)образ диска (1)хаки (1)сенсоры (1)сенсорная сеть (1)Wine 11.8 (1)ldlc (1)ретейлеры (1)жизнь на марсе (1)картон (1)военные технологии (1)АГС (1)альтернативная гражданская служба (1)Минтруд (1)призыв (1)список профессий (1)трудоустройство (1)APT 3.3.0 (1)амодеи (1)Little DirectMedia Layer (1)LinuxOnTab (1)digicert (1)ложное срабатывание (1)инсталляция (1)кулер (1)техноблогеры (1)кондиционер (1)warehouse deal (1)amazon warehouse (1)cpe (1)fwa (1)фиксированный доступ (1)беспроводной доступ (1)model 3 (1)старые автомобили (1)волновая функция (1)коллапс волновой функции (1)время (1)fractal design (1)корпус пк (1)госорганы (1)закрытый код (1)почта банк (1)лесные пожары (1)камеры с ии (1)kde plasma (1)kde plasma 6.6 (1)бета (1)линукс (1)thermos (1)термосы (1)посуда (1)травмы (1)докинз (1)хостинг-провайдеры (1)DNS-резолвинг (1)складские роботы (1)logistika expo (1)интернет-провайдер (1)интернет-провайдеры (1)mercedes (1)физические кнопки (1)элементы управления (1)финалисты (1)банки за границей (1)нетология (1)autosar (1)компиляция (1)read it club (1)ит-литература (1)техническая литература (1)посылки из-за рубежа (1)отслеживание посылок (1)электрошокер (1)нательные камеры (1)mac-адреса (1)axon (1)АСБИ (1)контроль трафика (1)интернет-цензура (1)ФГУП ГРЧЦ (1)обход блокировок (1)зависание (1)роса (1)peloton (1)фитнес (1)плелисты (1)коллаборация (1)ЧОП (1)охрана (1)уличная сигнализация (1)охрана вокруг дома (1)охрана территории (1)вооруженная охрана (1)антитела (1)ред ос м (1)mig (1)мониторинг интернета (1)цифровое наблюдение (1)деструктивное поведение (1)цифровые права (1)онлайн-активность (1)интернет-контроль (1)профилактика экстремизма (1)Task Explorer 1.8.0 (1)Task Explorer (1)Unexpected Keyboard 2.0.0 (1)Unexpected Keyboard (1)маркировка по (1)логотип (1)споры (1)wpp (1)системные администраторы (1)защищенный режим (1)убийство (1)преступление (1)улика (1)aicore (1)потребление памяти (1)падение дохода (1)контроль безопасности (1)osv (1)pt scs (1)sca (1)dependency firewall (1)registries (1)госданные (1)законопроект о регулировании ии (1)daikichi (1)wired tokyo 2007 (1)демоверсия (1)qBittorrent 5.2.0 (1)qBittorrent 5 (1)qBittorrent (1)Manifesta Agency (1)блок-схема (1)как стать архитектором (1)cleverdata (1)каталоги (1)сегментация (1)маркетинговые коммуникации (1)справочники (1)триггеры (1)атрибуты (1)введение в профессию (1)указ (1)регуляция (1)цифровизация девелопмента (1)технико-экономические показатели (1)phone link (1)cloudz (1)pheno (1)код подтверждения (1)rat (1)ai в программировании (1)системное мышление (1)Scrum (1)локальные оптимизации (1)метрики процессов (1)оптимизация процессов (1)светотехника (1)расчёт освещения (1)архитектурное проектирование (1)часть человека (1)sd-wan (1)межсетевой экран (1)межсетевой экран нового поколения (1)межсетевой экран фстэк (1)girl-agent (1)AQOS (1)росмолодежь (1)Mistral Medium 3.5 (1)Vibe Agents (1)DDR5-8000 (1)teamgroup (1)elite plus ddr5 (1)elite ddr5 (1)jedec-подход (1)армия (1)военные (1)inSales (1)чекаут (1)интернет-магазин (1)nanobanana (1)GPT-5.5 Instant (1)Дринкап (1)оскар (1)gamedev (1)отток кадров (1)технологическая среда (1)Glow 26.7 (1)Trusted Remote Execution (1)Node.js 26 (1)gpt-oss-120b (1)расширение (1)вредонос (1)криптовалютные биржи (1)proof-of-concept (1)nocode (1)Shutter Encoder 20.1 (1)Shutter Encoder 20 (1)RKN Block Checker (1)multi-token prediction (1)MTP drafters (1)LLM inference (1)психиатрия (1)обман (1)заблуждения (1)Subquadratic (1)long-context LLM (1)архитектура нейросетей (1)Kaspersky GReAT (1)вредоносный установщик (1)сочинение (1)облако mail (1)wayback machine (1)архивирование (1)накопители данных (1)переезды (1)buyback (1)обратный выкуп акций (1)Московская биржа (1)мотивация сотрудников (1)корпоративные финансы (1)tab (1)os2 (1)заказы онлайн (1)зарубежные товары (1)cleartext (1)кража учётных данных (1)browser security (1)devopsconf (1)remy (1)вычислительная мощность (1)shuanglin (1)самосвалы (1)беспилотные самосвалы (1)беспилотные грузовики (1)Postgres Pro Backup Enterprise (1)probackup (1)SPARK (1)o1 (1)etsy (1)усы (1)internet matters (1)городское проектирование (1)городское планирование (1)урбанистика (1)C-200 (1)ультразвуковой нож (1)solana (1)услуги (1)внешние аккумуляторы (1)перевозка (1)плутон (1)product (1)mylibrary (1)MyLibrary 5.0 (1)ToaruOS 2.3 (1)ToaruOS (1)Composer 1.5 (1)DPI Detector (1)день радио (1)попов (1)aitm (1)администрирование сайтов (1)день победы (1)pci-sig (1)pcie 8.0 (1)pci express (1)спецификация (1)скорость передачи данных (1)cnc (1)nso (1)TALOS-V2 (1)microgpt (1)disc soft (1)daemon tools lite (1)загрузки (1)загрузка файлов (1)конвейеры (1)финансовые маркетплейсы (1)медпомощники (1)мониторинг здоровья (1)Google Threat Intelligence (1)Agentic (1)incident response (1)Malware Analysis (1)Reverse Engineering (1)Dark Web Intel (1)AI в кибербезопасности (1)унифицированные коммуникации (1)корпоративные платформы (1)unified communications (1)суперапп (1)экосистема для бизнеса (1)muddywater (1)tsundere (1)castlerat (1)RapidRAW 1.5.5 (1)rl (1)соревнование по программированию (1)меры поддержки (1)дмитрий песков (1)lvfs (1)спонсоры (1)режим ии (1)саман (1)глина (1)отмена отправки (1)кибератаки в 2026 (1)таргетированный фишинг (1)государственные учереждения (1)правительственные сайты (1)steam controller 2 (1)скины (1)creative commons (1)мфц (1)годовщина (1)trinitron (1)walkman (1)nfc-платежи (1)wizardry (1)классические игры (1)лямбда-cdm (1)вселенная (1)большой взрыв (1)сколтех (1)сцепление (1)мотоспорт (1)откат (1)старые ос (1)bose (1)саундбары (1)сабвуферы (1)Believe (1)TuneCore (1)Flow Music (1)философия (1)SWE Atlas (1)anthropic institute (1)почтовый сервис (1)маскировка (1)контакты (1)Mesa 26.1.0 (1)Mesa 26.1 (1)Mesa 26 (1)Mesa (1)Chrome 148 (1)Copy Fail 2 (1)реакции (1)стили (1)приложения для windows (1)публикация приложений (1)Incus 7.0 LTS (1)накрутка показов (1)просмотры (1)учебные заведения (1)газинформсервис (1)eve online (1)ccp games (1)google fit (1)google health coach (1)152-фз (1)airtag (1)energizer (1)смарт-метки (1)child shield (1)Claude блокирует Россию (1)Xiaomi MiMo (1)IPO Anthropic (1)AI для разработчиков (1)прямые трансляции (1)участники (1)значки (1)вакансии и работа (1)фтс (1)at consulting (1)c3d (1)c3d toolkit (1)c3d labs (1)c3d modeler (1)конференция для разработчиков (1)инженерное по (1)геометрическое ядро (1)геометрическое моделирование (1)высокая нагрузка (1)краснодар (1)митапы в краснодаре (1)ит-мероприятие (1)магнит (1)magnit tech (1)магнит тех (1)фотоловушки (1)электроэнергетика (1)теплоэнергетика (1)мэи (1)IntelliJ (1)регулирование интернета (1)смартчасы (1)управление уязвимостями (1)ai-проекты (1)цифровой контроль (1)inditex (1)uap (1)информационная безопаность (1)claude 3.5 (1)volkov commander (1)сокращатель ссылок (1)qa lead (1)qa automation engineer (1)qa mobile (1)qa strategy (1)Yango (1)MLU B.V. (1)GDPR (1)продуктовая аналитика (1)aha26 (1)доклады для аналитиков (1)Hughesnet (1)Viasat (1)скорость интернета (1)Total Commander 11.57 (1)Total Commander 11 (1)Total Commander (1)killswitch (1)OpenWrt 25.12.3 (1)AI co-mathematician (1)повар (1)заказ еды (1)recaptcha (1)предустановленные сервисы (1)nikon d6 (1)nikon (1)geforce now (1)gfn (1)Inkscape 1.4.4 (1)inkscape 1.4 (1)Inkscape (1)DPI Checkers (1)FreeRDP 3.26 (1)Edge 148 (1)Gemini Nano (1)входящие звонки (1)происхождение (1)цифровой отпечаток (1)ploopy (1)проводная версия (1)джойстик (1)DOGE (1)переговоры (1)выходное пособие (1)BSD 3 (1)Parrot OS 7.2 (1)Parrot OS 7 (1)Parrot OS (1)Space Energy (1)Приморский (1)биология (1)рои (1)Hyprland 0.55.0 (1)NWinfo 1.6.3 (1)NWinfo 1.6 (1)Mojo 1.0b1 (1)Mojo 1.0 (1)Mojo (1)lay (1)юар (1)определение номера (1)распознавание номера (1)g02 (1)lenovo g02 (1)GPT-Realtime-2 (1)windows nt (1)символы (1)типографика (1)старый софт (1)углеродное волокно (1)Taobao (1)кампания (1)crimenetwork (1)дарксторы (1)unistore (1)собеседование (1)parker (1)поддержка клиентов (1)Ratty (1)tesla semi (1)электрогрузовики (1)Astra Migration (1)миграция ит-инфраструктуры (1)deepl (1)штат (1)регенерация (1)гоночные симуляторы (1)Forza Horizon 6 (1)Playground Games (1)игровые клипы (1)KillerPDF 1.3.0 (1)BetterMediaInfo 0.9 (1)PeaZip 11.1 (1)венчурные (1)лучшие стартапы (1)лучшие стартапы россии (1)лучшие стартапы россии 2026 (1)Маркетинг без Telegram (1)илья суцкевер (1)яндекс навигатор (1)Isowulf (1)wolfenstein 3d (1)деанонимизация (1)Veo (1)сео продвижение (1)сео-оптимизация (1)сео эксперт (1)поисковая оптимизация (1)поисковые алгоритмы (1)infra.conf 26 (1)yandex infrastructure (1)агрегаторы (1)ранжирование контента (1)Т1 Облако (1)коммунальное хозяйство (1)водоснабжение (1)джорджия (1)qts (1)trojan (1)ufactor (1)соответствие (1)фз-187 (1)compliance (1)госсопка (1)топливно-энергетическая отрасль (1)казахастан (1)азия (1)nbc (1)ENISA (1)defensive security (1)распределённые вычисления (1)доставка товара (1)срок действия (1)young con (1)интерактивность (1)вопросы и ответы (1)диалог (1)coursera (1)udemy (1)образовательные программы (1)образовательные платформы (1)объединение (1)курсы (1)progate (1)миграция бд (1)Turnitin (1)цхэд (1)янао (1)ред ос (1)отказ (1)Low Latency Profile (1)быстродействие ОС (1)марсианская миссия (1)индженьюити (1)Photoflare 1.7.0 (1)Photoflare (1)андрей карпатый (1)спячка (1)bsod (1)синий экран (1)неполадки (1)заводы (1)SparkyLinux 8.3 (1)SparkyLinux 8 (1)SparkyLinux (1)Горелкин (1)корпоративный мессенджер (1)коммуникации (1)dnsmasq (1)блокировка архивов (1)фильтрация изображения (1)фильтрация писем (1)фильтрация почты (1)нейронауки (1)инструменты коммуникаций (1)дивиденды (1)монеты (1)1 доллар (1)доллары (1)коллекционные монеты (1)монетный двор (1)отечественная электроника (1)data fest (1)Medicare (1)access (1)Pair Team (1)flora (1)хронические заболевания (1)health outcomes (1)ЕЦБ (1)финансовый сектор (1)AI-атаки (1)instructure (1)выкуп (1)Gboard (1)Rambler (1)силуанов (1)feram (1)безопасность контейнеров (1)софт-скиллы (1)хард-скиллы (1)взгляд на безопасность (1)оффлайн (1)обмен опытом (1)технологические решения (1)индустриальный код (1)unitree GD01 (1)InfoWatch ARMA (1)cemu (1)wii u (1)nintendo wii u (1)кража паролей (1)project suncatcher (1)pla (1)pure pla (1)scuf (1)scuf omega (1)scuf gaming (1)круиз-контроль (1)chrome os (1)конверсия (1)vk донат (1)AI-ассистент для разработки (1)модели для кода (1)MCP-Atlas (1)инструменты для разработчиков (1)super heavy (1)запуски (1)raptor (1)raptor 3 (1)database (1)db (1)бд (1)бд mysql (1)энтомология (1)комары (1)показания (1)android auto (1)MDASH (1)MediaInfo 26.05 (1)mediainfo (1)RevPDF 4.0 (1)Scrcpy 4.0 (1)Scrcpy (1)Fragnesia (1)продукт (1)продукт менеджмент (1)custdev (1)customer development (1)product management (1)2fa-аутентификация (1)мультифакторная аутентификация (1)Notion Developer Platform (1)Workers (1)External Agent API (1)автоматизация workflows (1)беспилотные авто (1)UEFI (1)Рикор (1)реестр российского ПО (1)x86 (1)российский BIOS (1)газонокосилка (1)конкурс инженерных проектов (1)Origin Lab (1)world models (1)игровые ассеты (1)обучающие данные (1)AI-лаборатории (1)симуляции (1)игровые данные (1)World Labs (1)лицензирование данных (1)отслеживание местоположения (1)таймеры (1)интернет-реклама (1)CoWoS (1)2 нм (1)А16 (1)AI-ускорители (1)фабрики (1)пассивный доход (1)сети передачи данных (1)сети и телекоммуникации (1)совмещение работ (1)ramp (1)контрафакт (1)виртуальные операторы (1)Hummingbird (1)т-двор (1)просветительская деятельность (1)электробайки (1)нарушители (1)пдд (1)frontend react (1)озеро тахо (1)тахо (1)энергия (1)литий-ион (1)литий-серные (1)серчинформ киб (1)защита от утечек информации (1)Xperia (1)Xperia 1 VIII (1)флагманы (1)внешние сервисы (1)закон о цифровых рынках (1)аварийное восстановление (1)disaster recovery (1)backup (1)draas (1)dt (1)threads (1)дейтинговые севрисы (1)vk знакомства (1)мок (1)частное облако (1)регтех (1)windows autopatch (1)тет-а-тет (1)reon pocket (1)кондиционеры (1)postgres pro enterprise manager (1)администрирование баз данных (1)белки (1)astra cloud (1)isomorphic labs (1)Fwupd 2.1.3 (1)nginx 1.31.0 (1)nginx 1.31 (1)automotive grade linux (1)Bun (1)принстон (1)списывание (1)кодекс чести (1)fedora (1)vmware workstation pro (1)марксизм (1)социализм (1)скорая помощь (1)медицина будущего (1)singularity (1)компьютерный корпус (1)монтаж (1)Grok Build (1)терминал (1)субагенты (1)SuperGrok Heavy (1)Ричард Сочер (1)You.com (1)рекурсивное самоулучшение (1)open-endedness (1)rainbow teaming (1)Peter Norvig (1)cma (1)ИИ-поверхность (1)MES (1)SMIC (1)foundry (1)legacy nodes (1)mature nodes (1)semiconductor capacity (1)ai-nativeenterprise (1)blade 18 (1)blade (1)Roo Code (1)Cline (1)ракета (1)инновации (1)пилотирование технологий (1)индустриальное применение (1)диптех-стартап (1)password manager (1)перенос (1)конкурсы (1)порнография (1)саундтрек (1)национальный реестр (1)библиотека конгресса (1)мидлы (1)синьоры (1)онлайн митап (1)spaceweb (1)малый средний бизнес (1)мсб (1)сбои в работе (1)продуктовый цикл (1)ускорение продуктового цикла (1)Wikipedia File Explorer (1)ExploitBench (1)CPU-Z 2.20 (1)Nocturne (1)Nocturne 1.0 (1)Exam GH-600 (1)Agentic AI Developer beta (1)Астероид 2026 JH2 (1)jcb (1)двигатели внутреннего сгорания (1)водородные двигатели (1)верификация личности (1)Konami (1)Минпросвещение (1)OpenAI Codex (1)Lake Tahoe (1)Liberty Utilities (1)энергосеть (1)personal finance (1)plaid (1)банковские аккаунты (1)Forward-Backward (1)Belief-FB (1)Rotation-FB (1)sim-to-real (1)адаптация моделей (1)Restik (1)складской учет (1)фудкост (1)компьютерное мошенничество (1)Opexus (1)Debian 13.5 (1)Wine 11.9 (1)Halupedia (1)plants vs zombies (1)popcap (1)mantic (1)мальта (1)бесплатный доступ (1)ApexGO (1)asus rog (1)asus rog ally (1)xreal (1)r1 (1)предзаказы (1)r (1)jabber.ru (1)jabber (1)xmpp (1)Rescuezilla 2.6.2 (1)Rescuezilla (1)Memtest86+ 8.10 (1)Memtest86+ 8 (1)Memtest86+ (1)Аврора ТВ (1)умный тв (1)паранойя (1)ModuleJail (1)SECAI (1)verizon (1)tmobile (1)Код человечности (1)figure (1)figure 03 (1)f.03 (1)сортировка (1)теледроид (1)Cats Lock (1)общественная палата (1)остров (1)микрогосударства (1)sensay (1)рассылки (1)ftc (1)a380 (1)встреча сообществ (1)кибепреступники (1)AI-специалисты (1)IT-сокращения (1)AI-native development (1)Samsara (1)AI workflows (1)system (1)привилегии (1)автоудаление чатов (1)Bloomberg (1)нрс (1)модульные ЦОД (1)AI-кластеры (1)ДАТАРК (1)Direct-to-Chip (1)иммерсионное охлаждение (1)нагрузка на стойку (1)ai slop (1)баг-рапорты (1)security reports (1)asl (1)амслен (1)язык жестов (1)hand wave (1)Sandia National Laboratories (1)NextSilicon (1)hpc (1)double precision (1)data flow architecture (1)ядерное моделирование (1)сувениры (1)рабочая коммуникация (1)геймдевелопмент (1)orange pi 5 (1)rockchip 3588 (1)манипулирование (1)secureboot (1)картель (1)картельный сговор (1)водный транспорт (1)icewhale technology (1)zimacube (1)intel core 12 (1)zimaos (1)exchange server 2016 (1)exchange server 2019 (1)outlook web access (1)курсор (1)указатель (1)концепция (1)шаблонность (1)правши (1)левши (1)амбидекстр (1)цифровизация производства (1)цифровизация предприятия (1)лекция (1)екатеринбург (1)тёмная материя (1)loop (1)модем (1)программы (1)устаревшие технологии (1)phone dialer (1)ThinkPad P14s Gen 7 (1)wwdc26 (1)Erlang 29 (1)Phosh 0.55.0 (1)Firefox 151.0 (1)Firefox 151 (1)генерация контента (1)Unreal Tournament (1)retrogaming (1)porting (1)инженер внедрения (1)fde (1)alice ai art (1)ординатура (1)отбор кандидатов (1)киносценарий (1)молодые авторы (1)level-5 (1)SandboxAQ (1)биофарма (1)drug discovery (1)Large Quantitative Models (1)LQM (1)материаловедение (1)молекулярная динамика (1)микросервисная архитектура (1)михаил мишустин (1)отечественный продукт (1)потеря данных (1)tip (1)soar (1)Blackstone (1)AI cloud (1)compute-as-a-service (1)mena (1)физические модели (1)инженерное моделирование (1)playstation plus (1)ps plus (1)эксклюзивы (1)внешний аккумулятор (1)отключение питания (1)pokemon (1)Clear Gate (1)токен доступа (1)успеваемость (1)образование в США (1)NAEP (1)день технологий (1)лекции (1)научпоп (1)мтуси (1)it-стартапы (1)StemDeck (1)компектующие (1)контракты (1)контрафактное по (1)сервисная архитектура (1)сервисное обслуживание (1)дисковые накопители (1)инфраструктурное по (1)аспиранты (1)адъюнкты (1)exodus (1)водяное охлаждение (1)подводные дата-центры (1)HPSC (1)Microchip (1)бизнес в европе (1)игровой монитор (1)IPS-матрица (1)vr-тренажер (1)битвы роботов (1)инфраструктурные системы (1)onyx (1)onyx boox (1)ресурсный подход (1)Нейросети в ИБ (1)митапы в спб (1)пластическая хирургия (1)биржи (1)биржи в криптовалюте (1)эталон (1)Kynooe (1)Kynooe One (1)роборука (1)фиан (1)Gemini 3.5 (1)humble (1)альцгеймер (1)чай (1)квантовый компьютер (1)equal1 (1)racq (1)Mozilla Thunderbird 151.0 (1)Mozilla Thunderbird 151 (1)Thunderbird 151 (1)ForgeZero 1.9.0 (1)ForgeZero (1)CrystalDiskInfo 9.9.0 (1)CrystalDiskInfo (1)amazon web services (1)m3 ultra (1)m3 (1)prd (1)кража аккаунтов (1)DietPi 10.4 (1)obsidian (1)управление ит-бюджетом (1)цифровизация бизнеса (1)тсо (1)окупаемость проекта (1)western digital (1)hndl (1)1000x (1)herman miller (1)игровая мебель (1)стол (1)столешница (1)хакинг (1)АтомМайнд (1)ТВЭЛ (1)рнф (1)протезирование (1)киберпанк (1)российское оборудование (1)серверные стойки (1)медиасервер (1)шопинг (1)MyCompany 6.2 (1)MyCompany 6 (1)MyCompany (1)китайские чипы (1)Huawei Ascend 950 (1)wade mode (1)режим перехода вброд (1)водоемы (1)преграды (1)AI regulation (1)nutrition labels (1)маркировка ИИ (1)AI-продукты (1)аккредитация ИИ (1)энергоэффективный ИИ (1)семья (1)рождение детей (1)поддержка сотрудников (1)Krafton (1)PUBG (1)emmi (1)производственные системы (1)игровой пк (1)raspberry pi 5 (1)одноплатные компьютеры (1)поиск по архивам (1)beyond the dark (1)панспермия (1)астробиология (1)приложение для android (1)средний бизнес (1)Robin (1)Co-Scientist (1)аккредитация it (1)льготы для it (1)требования к сайту (1)требования законодательства (1)сканирование сообщений (1)автоматическая модерация (1)виртуальный музей (1)longson (1)longarch (1)иртыш (1)трамплин электроникс (1)GPT-5.6 (1)суверенный ии (1)ai-платформа (1)стики (1)дрифт (1)дрифт стиков (1)driftguard (1)отдел кадров (1)bolt (1)Kitty 0.47 (1)Wireshark 4.6.6 (1)Wireshark 4.6 (1)wireshark 4 (1)Ubuntu Core 26 (1)Ubuntu Core (1)интеграция 1с (1)интеграции с it- системами (1)http-сервисы (1)real-time (1)розничная продажа (1)автоматизация продаж (1)гаддежты (1)мтб (1)intuit (1)лайвкодинг (1)ooxml (1)диагностика заболеваний (1)набор (1)василиса (1)браузерный движок (1)southwest (1)авиаперевозчики (1)роботы-животные (1)куртка (1)вибрации (1)звуковые волны (1)развитие стартапа (1)тайм-менеджмент (1)веб-приложение (1)лаборатория ии (1)полуроводники (1)мобильная безопасность (1)reasoning model (1)гипотеза Эрдёша (1)unit distance problem (1)дискретная геометрия (1)математическое доказательство (1)ИИ в науке (1)Noga Alon (1)Melanie Wood (1)Thomas Bloom (1)Flipper One (1)Спроси YouTube (1)Colossus 1 (1)neocloud (1)графиня (1)ExportAI Initiative (1)EXIM (1)mictosoft (1)Самарский университет (1)воздушный винт (1)пропеллер (1)аэродинамика (1)снижение шума (1)тяга (1)marshall (1)milton anc (1)организационные меры в иб (1)управление персональными данными (1)УПРАВЛЕНИЕ СООТВЕТСТВИЕМ НМД (1)контроль согласий (1)испдн (1)операторы ПДн (1)наличные (1)наличные деньги (1)eos r6 v (1)canon eos r6 v (1)видеокамера (1)съёмка видео (1)g suite (1)коммерческое использование (1)mx master 4 (1)тактильная обратная связь (1)Знай наших (1)леший коннект (1)управление роутерами (1)ssj100 (1)нервы (1)astra (1)AI-ассистент для разработчиков (1)Google IO 2026 (1)Киберкомандование США (1)военные кибероперации (1)АНБ (1)фонд викимедиа (1)mediawiki (1)RAMPART (1)Clarity (1)кубсаты (1)детектор нейтрино (1)нейтрино (1)криптоматы (1)OpenBSD 7.9 (1)OpenBSD 7 (1)Tails 7.8 (1)RHEL 10.2 (1)RHEL 10 (1)RHEL (1)red hat enterprise linux (1)фнс it-компании (1)фнс взыскание долгов (1)блокировка счетов (1)выход на биржу (1)космические компании (1)sec (1)минторг сша (1)субсидии (1)Nvidia B200 (1)Brett Adcock (1)consumer AI (1)AI hardware (1)AI-музыка (1)AI-каверы (1)Udio (1)nx (1)бронирование билетов (1)зоотовары (1)universal music (1)каверы (1)Ardour 9.5 (1)MOSS (1)edifier (1)att (1)медный кабель (1)телефонные сети (1)Клив Молер (1)matlab (1)реальныепримерыpython (1)корпоративные ит-системы (1)увольнение сотрудников (1)дринкит (1)напитки (1)standoff hacks (1)киберзащищенность (1)недопустимые события (1)багхантеры (1)starbucks (1)технологические тренды (1)техлиды и архитекторы (1)q1 (1)yu7 (1)YU7 GT (1)электрокар (1)автомобиль (1)кроссовер (1)рассказы (1)оригинальность (1)DeLonghi (1)интеллектуальные права (1)deep agents (1)evaluation (1)multi agents (1)bumblebee (1)ONLYOFFICE DocumentServer 9.4.0 (1)ONLYOFFICE DocumentServer 9 (1)ONLYOFFICE DocumentServer (1)AI-пилоты (1)мастермайнд (1)SoundSwitch 7 (1)SoundSwitch (1)расширяемость (1)аннулирование (1)google cloud platform (1)WordPress 7.0 (1)манга (1)комиксы (1)google диск (1)UFO.Hosting (1)Stark Industries (1)WorkTitans (1)FIOD (1)забастовки (1)bungie (1)destiny 3 (1)зарубежные счета (1)tdk (1)nhk (1)GigaCowork (1)Morse Code (1)GPT-4.5 (1)Nitrux 6.1.0 (1)Nitrux 6 (1)GNOME Commander 2.0 (1)GNOME Commander (1)ayaneo (1)konkr (1)pocket block (1)наводнение (1)дожди (1)pixel watch (1)steam controller puck (1)puck (1)direct memory access (1)dma (1)valorant (1)античит (1)iommu (1)xilinx (1)msaas (1)artifact signing (1)cybercab (1)rxjs (1)angular (1)reactive programming (1)обучение программированию (1)cisa (1)вксл (1)AnyDesk 9.7.4 (1)Nemotron-Labs Diffusion (1)mountain (1)react.js (1)drive (1)google slides (1)logo (1)design (1)PuTTY 0.84 (1)PuTTY (1)Blood (1)Penn (1)TileOS 2.0 (1)TileOS (1)unreal engine 6 (1)ue6 (1)epic (1)rocket league (1)движки (1)авикакатастрофы (1)генерация звука (1)apkpure (1)утечка даных (1)альфа-банк (1)Antigravity 2.0 (1)уязвимость Apple M5 (1)white house app (1)white house (1)госслужащие (1)суммы минковского (1)выпуклые фигуры (1)церковь (1)anker (1)anker solix (1)портативные аккумуляторы (1)портативные батареи (1)NetBeans 30 (1)NetBeans (1)Grok 4.5 (1)gsd (1)supply chain attacks (1)массовые вызовы (1)иткс (1)raptor lake (1)Tau Scaling (1)LogicFolding (1)санкции США (1)тяньгун (1)шэньчжоу (1)шэньчжоу-23 (1)пилотируемые полёты (1)сервисы такси (1)слабовидящие (1)чтение с экрана (1)работа с текстом (1)релиз-менеджмент (1)ии-кодинг (1)wafer-scale (1)1T open-weight (1)OpenAI контракт (1)750 МВт (1)4 трлн транзисторов (1)GPU alternative (1)cdn (1)сеть доставки контента (1)злоумышленники (1)атаки маршрутизации (1)dnsmanager (1)возобновляемая энергетика (1)ветровая энергия (1)газ (1)поход (1)onlyfans (1)runtime (1)кросс-платформенность (1)выручка компаний (1)нпс (1)сбор денег (1)сбор средств (1)фича-флаги (1)front-end (1)дефицит чипов (1)блокировки интернета (1)серийный номер (1)кыргызстан (1)атаки нулевого дня (1)бухгалтер (1)бухгалтерский учет (1)бухгалтерия и программисты (1)умные браслеты (1)cloudru (1)beeline cloud (1)Таир-45 (1)Рубинар (1)лзос (1)моторика (1)ребрендинг (1)попутчик (1)ubuntu pastebin (1)pdlc (1)сбертех (1)KodikScan (1)DeepSeek Code (1)письма (1)MKVToolNix 99.0 (1)MKVToolNix (1)mkv (1)норвегия (1)большая языковая модель (1)национальная библиотека (1)huawei oceanstor bcmanager (1)флэш-память (1)самообучение (1)эмуляция игр (1)обратная совместимость (1)производительность игр (1)avanpost identity cloud (1)ps4 slim (1)google io (1)планшетный пк (1)глобальные центры (1)productivity (1)headcount (1)psp (1)playstation portable (1)сумки (1)аксессуары (1)геймдизайн (1)tinygrad (1)VibeCraft (1)создание сайтов (1)MX Linux 25.2 (1)MX Linux 25 (1)MX Linux (1)краулеры (1)инклюзивность (1)AI-сервис (1)OSA (1)контроль качества (1)автоматический контроля (1)ferrari (1)luce (1)минэнерго (1)военная техника (1)Грузия (1)грузинский лари (1)стейблкоин (1)Tether (1)razr (1)партнерские программы (1)коды (1)dsl (1)ebpf (1)типобезопасность (1)книги по программированию (1)накладные наушники (1)momentum (1)hi-res audio (1)aptx lossless (1)dolby atmos (1)платное образование (1)claude security (1)aws api (1)url-адреса (1)слеш (1)http api (1)rest api (1)эйчар (1)работа с персоналом (1)рекрутинг в it (1)лонгриды (1)журналы (1)печатные издания (1)пресса (1)openapi (1)Смотри ЕГЭ (1)РТКОММ (1)usergate summa (1)usergate client (1)эскплоит (1)сигнатура (1)затраты на ИИ (1)крэт (1)камаз (1)basis (1)mysql (1)ядро земли (1)AISI (1)клавиша (1)Rhino Linux 2026.1 (1)Rhino Linux 2026 (1)Rhino Linux (1)BetterMediaInfo 0.10.0 (1)панель управления (1)control panel (1)nvidia app (1)карьера в сша (1)пенсия (1)опыт (1)ужасы медицинских данных (1)цельс (1)варим ml (1)healthtech (1)vmbitrix (1)magicos (1)загрузочный экран (1)joomla 5 (1)swg (1)dlp-системы (1)коммуникация (1)Sway 1.12 (1)Sway (1)микс (1)свайп-жесты (1)свайп-меню (1)мобильный UX (1)напоминания в задачах (1)календарь задач (1)bamby lab (1)forbes (1)мгту.им.баумана (1)apim безопасный api (1)sds (1)селфи (1)паспорта (1)лидерборд (1)git-история (1)shadow AI (1)Контур.Эгида (1)внутренние угрозы (1)корпоративная инфраструктура (1)контроль сотрудников (1)уолл-стрит (1)мвм (1)Ашраф Алькарми (1)облачное хранение (1)Dropbox Dash (1)акции с двойным голосом (1)технотекст (1)спутниковый спектр (1)Cloud and AI Development Act (1)акция_FiirstVDS (1)vds-хостинг (1)скидки на VDS (1)детекция лиц (1)распознавание UHP (1)идентификация лиц (1)поиск всего (1)навыки ии (1)чек-лист (1)officejet (1)pico (1)axe (1)postgres axe (1)аналитические платформы (1)аналитические системы (1)выезд из страны (1)american airlines (1)нацбанк Беларуси (1)kakao (1)kakaotalk (1)high availability (1)планы развития (1)мобильная версия (1)катер (1)золото (1)ви.tech (1)аналитики (1)мероприятие для разработчиков (1)senior qa (1)senior product manager (1)senior product analyst (1)senior engineer (1)techlead (1)dump (1)pycon (1)pyconrussia (1)иволга senior camp (1)GalaxyVS (1)Tianhe (1)AlmaLinux 10.2 (1)AlmaLinux 10 (1)AlmaLinux (1)арктика (1)пространственный звук (1)Cursor Automations (1)raspberry pi 6 (1)beni (1)mondo robotics (1)запись видео (1)оператор (1)HWiNFO 8.48 (1)aws cloud (1)гиперскейлеры (1)kubevirt (1)ouroboros (1)прототипирование (1)ускорение разработки (1)промышленная инженерия (1)Head Over Heels (1)trade-in (1)iphone 16 (1)sos (1)space cadet (1)аркады (1)аркадные игры (1)кузяев (1)ЭР-Телеком (1)мобилка (1)dnd (1)flutter (1)dart (1)ос аврора (1)multistatus (1)веб-аналитика (1)мониторинг сайта (1)infodiode (1)synaptics (1)Coralboard (1)штормы (1)ураганы (1)землетрясения (1)алгоритм (1)автостоянка (1)автопарковка (1)платная стоянка (1)парковка в ЖК (1)охрана автомобиля (1)угон (1)повреждение автомобиля (1)движок (1)дизайн игр (1)система резервного копирования (1)архитектура бэкапа (1)ит-инфраструктура к2тех (1)googlebook (1)aluminium os (1)Maya (1)The Scholastics (1)Wigmund (1)инди-студия (1)выбор профессии (1)destruction allstars (1)lucid (1)рейсинг (1)Project Lightwell (1)open-source security (1)Autopilot (1)self-driving (1)Coze (1)отслеживание пользователей (1)эргономичность (1)офисная работа (1)частные продажи (1)агат (1)рапира (1)sothebys (1)динозавр (1)тираннозавры (1)динозавры (1)окаменелости (1)скелет (1)YASKAWA (1)Robotics Innovation Center (1)SDR (1)Zynq UltraScale+ (1)цифровая обработка сигналов (1)спектральный анализ (1)прибыльность (1)лос (1)летучие органические вещества (1)itil (1)windows server 2016 (1)имя хоста (1)Developer Habits Report (1)продуктивность разработчиков (1)автоматизация кода (1)robinhood (1)ценные бумаги (1)fast mode (1)Super-Agent benchmark (1)Online-Mind2Web (1)Coding (1)Opus 4 (1)opus 4.7 токены (1)ojai (1)waymo ojai (1)zeekr (1)geely (1)беспилотное такси (1)минивэн (1)PeerTube 8.2 (1)Calibre 9.9 (1)last.fm (1)прослушивание (1)СУБД SQLite (1)SQLite Bug Forum (1)управление персоналом в it (1)hrm (1)пеший маршрут (1)pandas (1)PyCon Russia (1)steam deck oled (1)серверная виртуализация (1)ИТ-затраты (1)TCO (1)управление ИТ-активами (1)ИТ-бюджет (1)дизайн-токены (1)гиперконвергенция (1)hci (1)видеонаблюдение в облаке (1)stackai (1)таскборд (1)фьючерсы (1)Shanghai Futures Exchange (1)CME (1)активисты (1)финансовая инфраструктура (1)ryzen (1)athlon (1)ryzen 6000 (1)кража информации (1)защита по (1)OpenSearch Serverless (1)retrieval (1)machine-generated traffic (1)sdlc (1)таск-трекер (1)перерасход (1)безопасность кода (1)эмбеддинг (1)веб-браузеры (1)сопровождающий (1)эксплуатация (1)ркк энергия (1)инсайдерская информация (1)1c (1)химическая промышленность (1)analog devices (1)bluetooth ble (1)заправки (1)мобильные телефоны (1)мчс россии (1)пожарная безопасность (1)сапборды (1)отдых на природе (1)отдых после работы (1)отдых на море (1)отдых и сон (1)отдых от ит (1)poc (1)пульсары (1)ценовая политика (1)TradeCore (1)жалоба (1)скорость воспроизведения (1)факультативы (1)звуковые карты (1)creative technology (1)SteaMidra (1)cargo (1)LFM2.5-8B-A1B (1)Fwupd 2.1.4 (1)fedora linux 42 (1)fedora linux 43 (1)wix (1)конструктор сайтов (1)AI Marketplace (1)образы (1)ориентирование (1)облачные консоли (1)Chan Zuckerberg Initiative (1)BioHub (1)alphafold 3 (1)Rust 1.96 (1)рецензия (1)23andme (1)генетические данные (1)цифровые помощники (1)уголовные дела (1)расследования (1)научный телеграф (1)центарльный университет (1)московский планетарий (1)галактический патруль (1)byok (1)cognition (1)devin (1)InVault (1)квантовые процессоры (1)хоррор-игры (1)FluentCleaner (1)с-терра (1)уборка (1)бытовые роботы (1)gnome circle (1)4k (1)CNN (1)зависимость от социальных сетей (1)рт-информ (1)цербер (1)код безопасности (1)цифровые решения (1)реактор (1)РИТМ-200С (1)ПЭБ-106 (1)Wine 11.10 (1)СУБД MariaDB 12.3.2 (1)СУБД MariaDB 12.3 lts (1)MariaDB 12.3 lts (1)mariadb 12 (1)MariaDB (1)call of duty warzone (1)cod warzone (1)cod (1)call of duty (1)call of duty modern warfare 4 (1)activision (1)огнестрельное оружие (1)entra id (1)ии-гаджеты (1)ии-устройства (1)limitless (1)flathub (1)flatpak (1)jqwik (1)тестовые фреймворки (1)инструкции для ии (1)paint.net (1)коты (1)отель (1)рост тарифов (1)ветряные генераторы (1)ветряные турбины (1)aomedia (1)avm (1)кодировщик (1)космические аппараты (1)тарелки (1)рендеры (1)доставка грузов (1)доставка грузов на орбиту (1)венчурные фонды (1)обучение сотрудников (1)летательные аппараты (1)Газпром СПКА (1)аиб (1)эрдёш (1)ramz (1)MLLM (1)промпт (1)самозанятый (1)рекорды (1)enhanced games (1)wada (1)допинг (1)спортсмены (1)препараты (1)фармакология (1)Rust Coreutils 0.9.0 (1)Ubuntu 26.10 Stonking Stingray (1)Ubuntu 26.10 (1)Stonking Snapshot 1 (1)Recordly (1)Servo 0.2.0 (1)bluetooth-динамик (1)терроризм (1)разворот (1)документация (1)объяснение (1)передача знаний (1)традиции (1)разгон памяти (1)xmp (1)MSA (1)MiniMax Code (1)computer use (1)МТК (1)безработица (1)диверсии (1)подводные аппараты (1)oura ring (1)ring 5 (1)кольцо (1)трекер (1)детские товары (1)ритейл в облаке (1)ритейлер (1)ритейл-медиа (1)аутсорс (1)аутсорсинг разработки (1)аутстаффинг (1)аутстафф (1)аутсорсинг деловых процессов (1)азербайджан (1)ps2 (1)ps2 slim (1)портативная консоль (1)playstation 2 (1)файрвол (1)сравни.ру (1)американская федерация учителей (1)aft (1)Ollama Cloud (1)большая контекстная модель (1)MSA архитектура (1)открытая модель (1)1M токенов (1)zero data retention (1)вычислительные ресурсы (1)биоугрозы (1)биологические угрозы (1)пандемия (1)эпидемия (1)surface laptop (1)surface laptop ultra (1)гибридные процессоры (1)контроль ии (1)ai игра (1)бизнес игра (1)управление командами (1)багханинг (1)пермский край (1)государственные сайты (1)интерактивная панель (1)rog xbox ally (1)rog xbox ally x (1)xreal r1 (1)rog xreal r1 (1)очки дополненной реальности (1)ar-очки (1)бандл (1)гибриды (1)противопожарная система (1)роман (1)элтекс (1)турбо облако (1)солнце (1)гелиосейсмология (1)ниу миэт (1)Qwen3.7-Plus (1)a2l (1)Audacious 4.6 (1)Audacious (1)audacious 4 (1)86Box 6.0 (1)86Box (1)Armbian 26.5 (1)прокси-серверы (1)декарбонизация (1)flexstrike (1)pulse elevate (1)Step 3.7 Flash (1)ultracode (1)проблема Эрдёша (1)Emergence World (1)BadHost (1)стартовая площадка (1)корпорации (1)cherry (1)cherry xtrfy (1)к2 нейротех (1)on-premise ai (1)программно-аппаратный комплекс (1)ПАК-AI (1)астрофизика (1)нейтронные звёзды (1)датчик присутствия (1)маркетинг в производстве (1)spring boot 3 (1)окончание поддержки (1)on-premises (1)ципр-2026 (1)ux ресерч (1)ux митап (1)ии митап (1)премия Хакатоны России (1)кибератак (1)угрозы иб (1)риски иб (1)F6 NTA (1)fastly (1)уголовное дело (1)работа сайта (1)профилирование (1)мониторинг производительности (1)heap memory (1)thread dump (1)термопрокладки (1)термопаста (1)углеродные трубки (1)Хорошее место (1)репутацияф (1)особенно хорошее место (1)Zcash (1)Orchard (1)Sapling (1)аудит безопасности (1)blockchain (1)льготы (1)prusa (1)ColorMix (1)cmyk (1)Linux Lite 8.0 (1)Linux Lite (1)QuickView 6.2.10 (1)Clonezilla Live 3.3.2 (1)colorful (1)nvidia rtx (1)dashlane (1)Intelligent Terminal (1)программное обеcпечение (1)экшен-камеры (1)basic (1)software defined networking (1)каско (1)забота (1)robotics (1)physical ai (1)mitre attack (1)аналоги (1)вендоры (1)лето (1)даяа (1)огород (1)каникулы (1)Goose (1)Whoop 5.0 (1)Whoop (1)стеклоочиститель (1)языковая модель (1)экономия памяти (1)биоэквайринг (1)биометрические данные (1)управление android (1)защита биометрии (1)uem-платформа (1)mdm-решение (1)рабочая станция (1)сточные воды (1)ранжирование (1)реранкинг (1)работодатель (1)ии-инжиниринг (1)ai engineering (1)langchain (1)fastapi (1)prometheus grafana (1)алматы (1)академия инноваторов (1)hp-16c (1)перевыпуск (1)16c (1)программируемые калькуляторы (1)ит-инфраструктуры (1)maxpatrol siem (1)vdsina (1)mchost (1)Чанчжэн-12А (1)чанчжэн (1)великий поход (1)long march (1)LM-12B (1)spa (1)сменный график (1)когнитивные способности (1)искусственные нейронные сети (1)сообщество разработчиков (1)Search as Code (1)ограничение трафика (1)DosZone Team (1)gta vice city (1)5g в россии (1)KliTek (1)K3 (1)сопла (1)coreutils (1)Scout (1)ViBench (1)эксперименты (1)RustDesk 1.4.7 (1)RustDesk 1.4 (1)BATorrent 1.0 (1)BATorrent (1)BATorrent 3.0 (1)удаление приложений (1)RapidRAW 1.5.6 (1)тест (1)заявка (1)гипервизор (1)morgan stanley (1)Model Capability Initiative (1)tomb raider (1)лара крофт (1)crystal dynamics (1)legacy of atlantis (1)ии-агент для бизнеса (1)корпоративная культура (1)люмен (1)платежный терминал (1)MAVEN (1)координационный центр домена .ru (1)книга (1)стихи (1)фпк (1)ctrl+z (1)яндекс музей (1)nvidia nemotron (1)nemotron 3 (1)NWinfo 1.6.4 (1)Trayy 3.1 (1)Trayy 3 (1)общение с клиентами (1)18+ (1)товары для взрослых (1)api-интерфейсы (1)поиск данных (1)индексация (1)структурированные данные (1)godot engine (1)шпионаж (1)пять глаз (1)спецслужбы (1)графические процессоры (1)подкачка (1)cooler master (1)сжо (1)гп (1)pop3 (1)mail.ru (1)выставки (1)шумы (1)frank rg (1)заявки (1)интернет-трафик (1)Cloudflare Radar (1)интернет-спутники (1)орбитальные аппараты (1)b2u (1)infostart cio camp (1)расходы на по (1)регата (1)математическая оптимизация (1)оптимизационное планирование (1)last mile (1)оптимизация маршрутов (1)математический решатель (1)техлид (1)discovery (1)delivery (1)догфудинг (1)кросс-функциональные команды (1)Авито База (1)Browser Choice Alliance (1)выбор браузера (1)Vivaldi (1)к2тех (1)миграция почты (1)microsoft exchange (1)корпоративная почта (1)apache2 (1)шмели (1)интеллект (1)ветер (1)Келси Хайтауэр (1)Privoxy 4.2.0 (1)Privoxy 4 (1)Privoxy (1)Warcraft 3 (1)Google Chrome 149 (1)Герметалл (1)ipnone (1)архивация данных (1)roku (1)roku os (1)covid-19 (1)игры для взрослых (1)Google Gemma (1)Opengram (1)Ardour 9.7 (1)Kimi Code (1)космодромы (1)мыс канаверал (1)bmx (1)портативные зарядки (1)портативные зарядные устройства (1)твердотельная электроника (1)Microsoft scout (1)стрелец а (1)ветер чёрных дыр (1)Голливуд (1)NAVEE (1)WaveFly 5X (1)экранолёт (1)полёты (1)Glukalka (1)киберзащита (1)Gemini CLI (1)OutWiker 4.0 (1)OutWiker (1)прерывание работы (1)speedometer (1)jetstream (1)molex (1)opencv (1)OpenCV 5.0 (1)voidzero (1)vite (1)vitest (1)web-разработка (1)ImageGenCam (1)chatgpt images (1)обработка (1)adafruit (1)flux (1)блоги (1)претензии (1)процесс обучения (1)vim (1)vim 9 (1)UMO 8 (1)Odysseus PewDiePie (1)NVIDIA Cosmos 3 (1)Anthropic S1 (1)рост стоимости (1)центра обработки данных (1)сетевая архитектура (1)rng (1)dasung (1)link 2 (1)внешний дисплей (1)IOCCC (1)bill of materials (1)libs (1)чп (1)тепловой разгон (1)iphone ultra (1)складной iphone (1)nokia n95 (1)n95 (1)ФСБ (1)Следственный комитет (1)задержание (1)казино (1)пмэф (1)пмэф 2026 (1)мтс банк (1)pt application inspector (1)финансовые системы (1)финансовые технологии (1)webos (1)tizen (1)роутинг (1)штаты (1)pt edtechlab (1)образовательная программа (1)обнаружение атак (1)расследование инцидентов (1)сетевой трафик (1)анализ трафика (1)мирэа (1)обучение кибербезопасности (1)учет ит-активов (1)управление активами (1)обсерватории (1)телескопы (1)мауна-кеа (1)футбол (1)BenQ (1)госсистемы (1)суп (1)супмаксинг (1)завтрак (1)пищевые привычки (1)Kimi Work (1)Monshot AI (1)нацпроекты (1)worm (1)exploit (1)ayya t1 (1)защищенный смартфон (1)диплом (1)бот (1)егэ по русскому (1)т-образование (1)ГосVPN (1)Siri AI (1)NVIDIA RTX 50 SUPER (1)pc (1)hardware (1)gddr7 (1)upgrade (1)graphic card (1)vga (1)научно-популярное (1)Emscripten 6.0 (1)Emscripten (1)IT-специалист (1)минтруда (1)unifi (1)root-доступ (1)ubiquiti (1)ruby (1)rubygems (1)bundler (1)период охлаждения (1)fsp (1)cannon (1)бп (1)видеокодек (1)ит-индустрия (1)skeleton (1)эстония (1)суперконденсаторы (1)яндекс книги (1)озвучка (1)озвучка текста (1)публичное размещение (1)avermedia (1)computex (1)веб-камера (1)док-станция (1)захват видео (1)Дизайн улыбки (1)защита приложений (1)воровство (1)сан-франциско (1)baremetal (1)выделенные серверы (1)Rspamd 4.1.0 (1)Rspamd 4 (1)hynix (1)hbm-память (1)openusd (1)работа с изображениями (1)temporal (1)одежда (1)белый VPN (1)apple foundation model (1)private cloud compute (1)k8s (1)MWS B2B Store (1)квантизация (1)TileRT (1)токены в секунду (1)сканирование контента (1)RayBan (1)онлайн-магазины (1)интернет-маркетинг (1)protein design (1)полистирол (1)co2 (1)углекислый газ (1)глобальное потепление (1)letsencrypt (1)патч (1)digiKam 9.1.0 (1)digiKam 9 (1)Qmmp 2.3.3 (1)си (1)твердотельные батареи (1)литий-ионные аккумуляторы (1)thermaltake (1)энергосистемы (1)электроснабжение (1)отключение электричества (1)криптомайнинг (1)безопасность windows (1)блокировка Roblox (1)тестирование ии (1)инструменты тестирования (1)естественный язык (1)система доменных имен (1)интернет-инфраструктура (1)HandBrake 1.11.2 (1)пилот (1)методика (1)ндв (1)гост р 56939 (1)гост р 56939-2024 (1)lets encrypt (1)BetterMediaInfo 1.0.0 (1)artemis iii (1)одноразовые телефоны (1)телекоммуникационные компании (1)Tools for Humanity (1)Orb (1)похищение данных (1)виртуальный оператор (1)стратегия (1)внимание (1)концентрация внимания (1)molot (1)обнаружение угроз (1)redwood (1)peak energy (1)Google AI Pro (1)Google AI Plus (1)xbox series x (1)велком-пак (1)welcomeaboard (1)апк (1)агропромышленный комплекс (1)цифровизация апк (1)управление данными (1)цифровая трансформация бизнеса (1)erp-система (1)интернет вещей iot (1)цкб рм (1)нанопаста (1)случайные числа (1)складная мышь (1)Cat Chess (1)НМИЦК имени Чазова (1)российский стек (1)совместимость ПО (1)Альт Сервер (1)Базальт СПО (1)container (1)diffusiongemma (1)Sigil 2.8.0 (1)Продвижение по новым правилам (1)Glow 26.9 (1)Анализ графов (1)Обработка состояний (1)Model checking (1)Ускорение запросов (1)Индексация данных (1)Рой дронов (1)зелёная волна (1)навигатор (1)покупки в интернете (1)ubisoft belgrade (1)ubisoft winnipeg (1)реорганизация (1)миссия (1)ядро процессора (1)повышение привилегий (1)аша шарма (1)терминальный агент (1)Max Mode (1)AI-агент для разработчиков (1)debian 12 (1)Debian 12 LTS (1)мехико (1)бутлуп (1)Agent Pay for Machines (1)AP4M (1)bpmn (1)bpm решения (1)мобильная ферма (1)раздел имущества (1)развод (1)внутриигровые покупки (1)внутриигровое имущество (1)stack overflow for agents (1)генераций кода (1)чанъэ-6 (1)чанъэ (1)лунный грунт (1)реголит (1)образцы грунта (1)r-vision (1)r-vision soar (1)standoff 17 (1)ARMA (1)Chrome 150 (1)uBlock Origin (1)скачивание (1)cybercamp (1)openair (1)1с предприятие (1)sla (1)сопровождение 1с (1)администрирование 1с (1)LabelStudio (1)hosted (1)SemiAnalysis (1)маржинальность (1)кладбище китов (1)starcraft 2 (1)phpbb (1)Fwupd 2.1.5 (1)OSSDEVCONF (1)OSSDEVCONF 2026 (1)запуск игры (1)GentleOS (1)mimo-xiaomi (1)pvsstudio (1)deezer (1)PhpStorm (1)Laravel (1)Symfony (1)Xdebug (1)PHPStan (1)PHP-разработка (1)подтверждение ит-аккредитации (1)роботы-змеи (1)робозмеи (1)линии электропередач (1)роботизированные змеи (1)человек (1)движение (1)энергопотребление ЦОД (1)rnn (1)transformers (1)trump t1 phone (1)trump mobile (1)htc (1)разбор (1)Kimi-K2.7-Code (1)coding model (1)MLS Bench (1)reasoning efficiency (1)Мустафа Сулейман (1)офисные работники (1)stackoverflow (1)Canadarm2 (1)HWMonitor 1.64 (1)ASI (1)mitm (1)dns over https (1)doh (1)шифрование трафика (1)samsung 990 pro (1)kyushu (1)kyushu electric power (1)жесткий диск (1)ssl-сертификаты (1)зарядки (1)адаптеры (1)which (1)шоссе (1)транспортный поток (1)пробки (1)TLS-сертификат (1)транзакции (1)GLM-5.2 (1)декларация (1)этика (1)BATorrent 4.0 (1)Wine 11.11 (1)manifest v3 (1)MV2 (1)mrbeast (1)подписчики (1)рекорд (1)видеоплатформы (1)aur (1)месть (1)саботаж (1)objectways (1)съемка (1)запись движений (1)yserver (1)yserver 1.0 (1)jabees (1)peace duo (1)костная проводимость (1)внутреннее ухо (1)kinetic cyber range (1)макет города (1)макет (1)тренировочный комплекс (1)Audacity 3.7.8 (1)Audacity 3 (1)Audacity (1)RevPDF 4.5 (1)RevPDF 4 (1)