Статьи по тегу

11 июня 2026, 12:00
Xiaomi выпустили MiMo Code — своего coding-агента
Вслед за Kimi ещё одна китайская компания обзавелась своим агентом. Основной упор в релизной статье китайцы делают на Max Mode: на каждом шаге агент генерирует 5 параллельных планов действий, а модель
1 июня 2026, 09:01
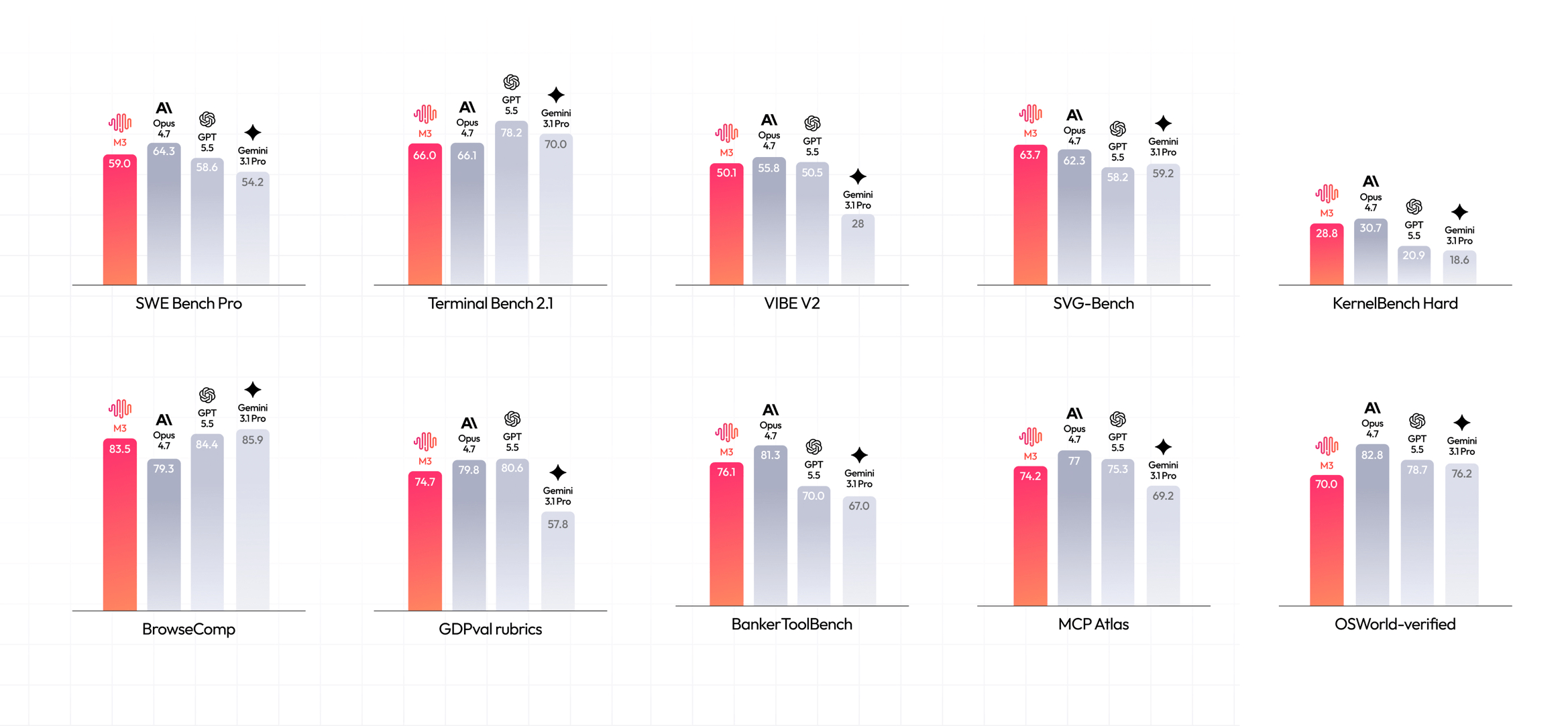
MiniMax M3 обошла GPT-5.5 на SWE-Bench Pro и выйдет с открытыми весами
MiniMax M3 вышла сегодня — это мощная языковая модель, которая одновременно предлагает frontier-уровень в кодировании и агентных задачах, контекст до 1 миллиона токенов и нативную мультимодальность (и
27 мая 2026, 13:49
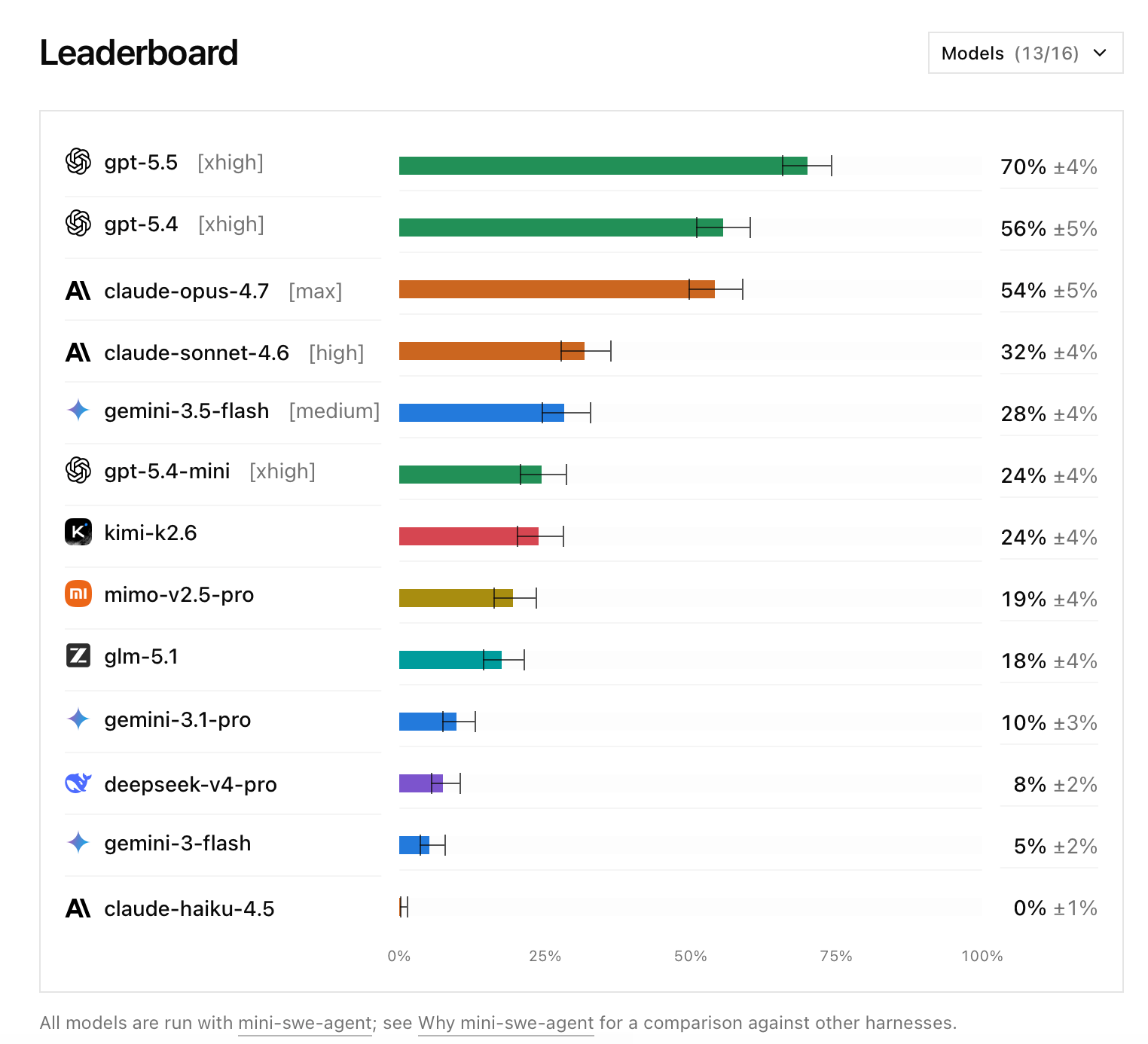
Свежий тест производительности DeepSWE: GPT-5.5 — 70%, Opus 4.7 — 54%
Новый тест производительности DeepSWE показал, что GPT-5.5 решает 70% задач по разработке ПО, тогда как Claude Opus 4.7 — 54%. На SWE-Bench Pro картина была ровно обратной: там Opus 4.7 занимал первое

21 мая 2026, 19:12
Выпуск Qwen3.7-Max: лучше Claude Opus 4.6 на SWE-bench Pro
Alibaba выпустила Qwen3.7-Max — закрытую флагманскую модель для долгоживущих агентов. В тестах: 35 часов автономной работы, 1158 вызовов инструментов, 10x ускорение CUDA-ядра. На SWE-bench Pro — 60.6,

13 мая 2026, 17:17
В Kodacode добавили Claude Opus 4.7
Передовая модель от Anthropic стала заметным шагом вперёд в программировании: в тестах на реальных задачах Cursor зафиксировал рост с 58% до 70%, CodeRabbit отметил улучшение recall на 10% при стабиль

6 мая 2026, 11:21
SubQ: первая LLM с контекстом в 12 млн токенов
Организация Subquadratic выпустила схема SubQ 1M-Preview — первую, по их словам, LLM на целиком субквадратичной архитектуре. Речь про SSA (Subquadratic Sparse Attention): вместо того чтобы сравнивать

21 апреля 2026, 14:04
В KodaCode теперь доступна топовая open source схема Kimi K2.6
По бенчмаркам схема держится рядом с закрытыми SOTA-моделями: SWE-Bench Pro — 58.6, SWE-Bench Verified — 80.2, топ среди open-source моделей. Сильные результаты и на BrowseComp и математических бенчах
10 апреля 2026, 19:59
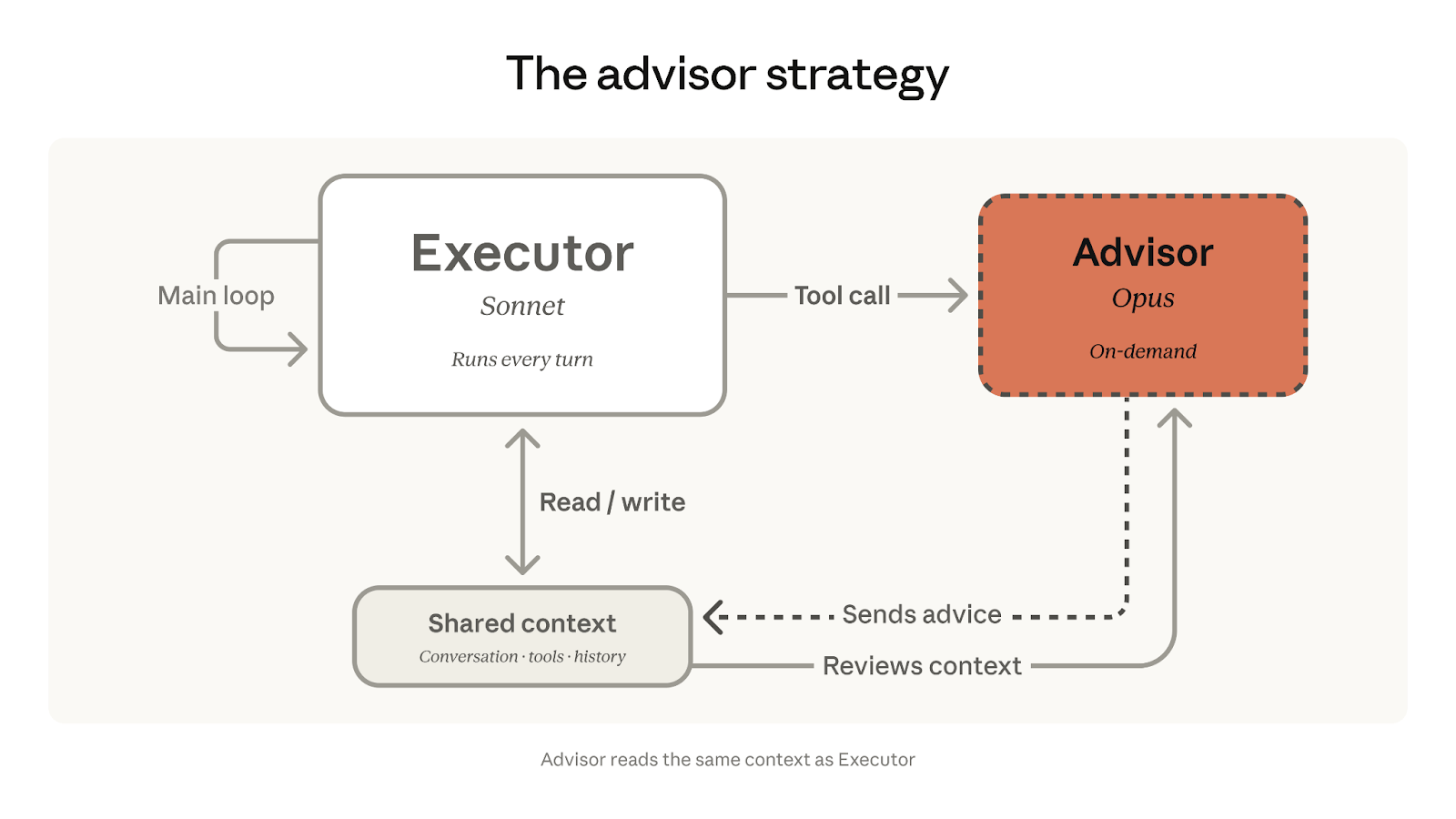
Anthropic научили Sonnet консультироваться с Opus
Anthropic выпустили advisor tool — инструмент, который позволяет запустить Opus как советника внутри задачи, которую выполняет Sonnet или Haiku. Работает так: Sonnet ведёт задачу от начала до конца —
7 апреля 2026, 19:57
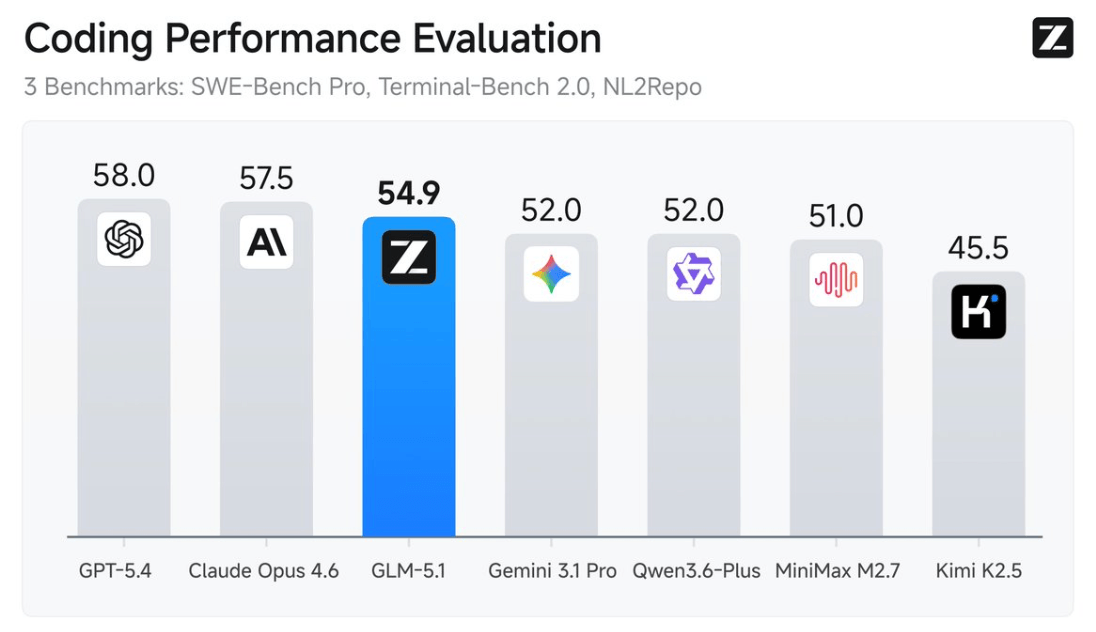
Z.ai выпустили GLM-5.1 — open-source схема, заточенную под долгие агентные задачи
Z.ai выпустили GLM-5.1 — новую флагманскую схема под MIT-лицензией, ориентированную на агентные инженерные задачи. По SWE-Bench Pro она набирает 58.4% против 57.3% у Claude Opus 4.6 и 57.7% у GPT-5.4.