Статьи по тегу

26 февраля 2026, 08:32
Anthropic сняла запрет на обучение опасных моделей на фоне давления Пентагона
Anthropic обновила свою Политику ответственного масштабирования (Responsible Scaling Policy, RSP) до версии 3.0 и убрала из нее ключевое обещание, которое организация давала с 2023 года: не обучать ИИ

25 февраля 2026, 12:58
Claude распознает бред в 94% случаев. GPT-5.2 поддакивает пользователю
Руководитель по ИИ в компании Arena Питер Гостев опубликовал Bullshit Benchmark — проверка из 55 бессмысленных вопросов, которые звучат умно, но не имеют смысла. Например: "Как скорректировать несущую

23 февраля 2026, 23:43
Красивый исходник усыпляет бдительность: Anthropic выяснила, когда пользователи перестают проверять ИИ
Anthropic опубликовала AI Fluency Index — первый количественный замер того, насколько грамотно люди работают с ИИ. Компания проанализировала 9 830 анонимизированных диалогов с Claude за неделю в январ
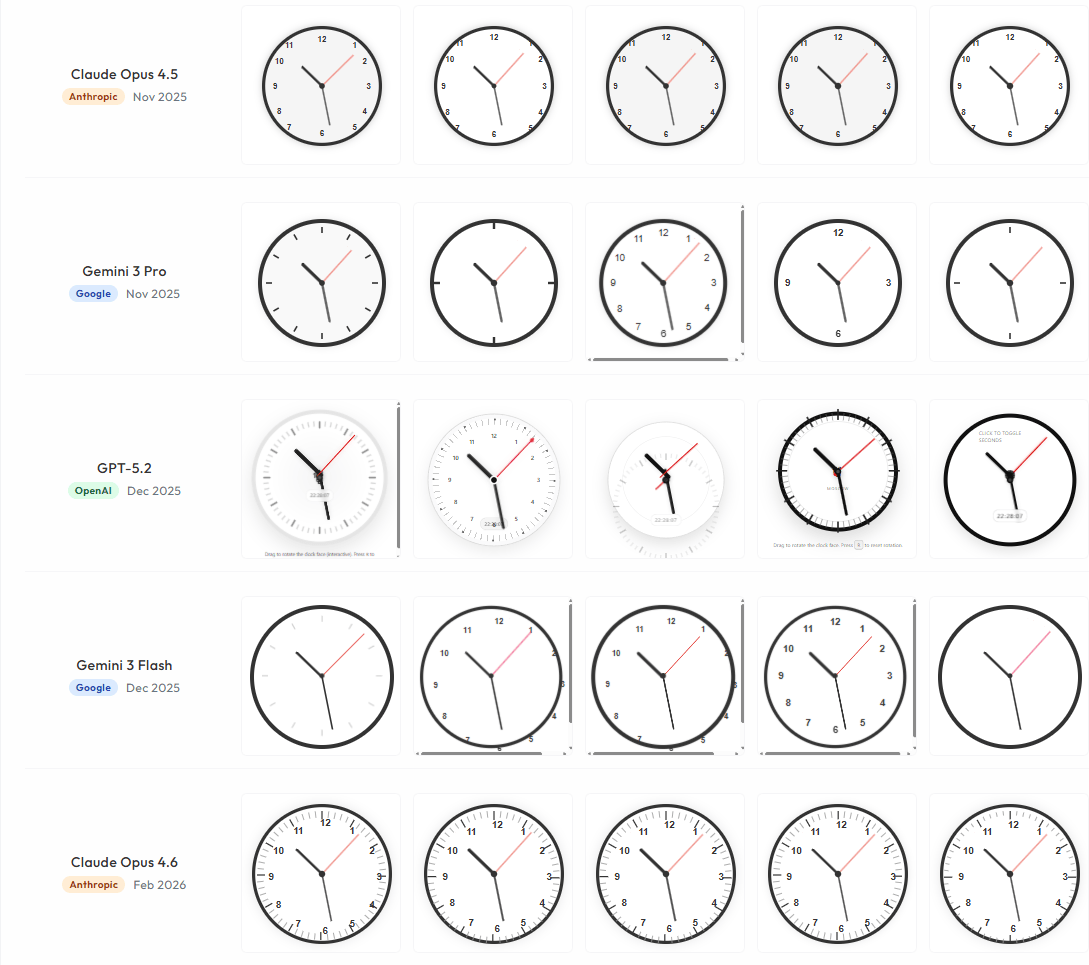
21 февраля 2026, 22:35
Полгода назад ИИ не мог нарисовать часы. Теперь — 5 из 5 попыток идеальны
Исследователь из Goodeye Labs Рэнди Олсон дал 22 ИИ-моделям — от GPT-3. 5 (2023) до свежих релизов 2026 года — один и тот же промпт: создать в одном HTML-файле работающие аналоговые часы с тремя стрел